
Da: Koen Verbeeck | Aggiornamento: 2018-08-09 | Commenti (4) | Related: 1 | 2 | 3 | 4 | Più > Integrazione di Servizi di Sviluppo

Free MSSQLTips Webinar: Iniziare con SSIS
scopri come iniziare con SQL Server Integration Services e come costruire un progetto SSIS con questa demo incentrata webinar.,
Problema
Vorremmo mantenere la cronologia nel nostro data warehouse per diverse dimensioni.Utilizziamo SQL Server Integration Services (SSIS) per implementare l’ETL (ExtractTransform e Load). Abbiamo provato il wizard Dimensionale integrato che cambia lentamente, ma le prestazioni sembrano scarse. Come possiamo implementare la funzionalità desiderata con componenti SSIS regolari?
Soluzione
Introduzione alle dimensioni che cambiano lentamente
Una dimensione che cambia lentamente (SCD) tiene traccia della storia dei suoi singoli membri., Ci sono diversi metodi proposti da Ralph Kimball nel suo libro The DatawarehouseToolkit:
- Tipo 1 – Sovrascrivere i campi quando il valore cambia. Nessuna storia iskept.
- Digitare 2-Creare una nuova riga con i nuovi valori per i campi. Extracolumns indicano quando nel tempo una riga era valida.
- Tipo 3-Mantenere il vecchio valore di una colonna in una colonna separata.
- Esistono più tipi di SCD, ma sono per lo più una combinazione ibrida di cui sopra.
In questo suggerimento, ci concentreremo sulla situazione di tipo 2. Illustriamocon un esempio., Abbiamo una semplice tabella che memorizza i dati dei clienti.

La colonna SK_Customer è una colonna con un identityproperty che genererà un nuovo valore per ogni riga. Vorremmo keephistory per l’attributo Location. Quando la posizione cambia da Anversa a Bruxelles, non aggiorniamo la riga, ma inseriamo un nuovo record:

Usando i campi ValidFrom e ValidTo, indichiamo quando un record era valido nel tempo. Viene generata una nuova chiave surrogata, ma la chiave aziendale-CustomerName-rimane la stessa., Quando viene caricata una tabella di fact, verrà eseguita una ricerca sulla tabella del cliente. A seconda del timestamp del record fact, verrà restituita una delle due righe. Ad esempio:
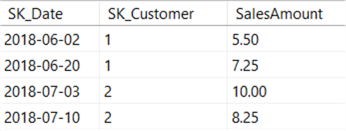
Tutti i fatti sono per lo stesso cliente. Quando si chiede il totale delle vendite amountfor CustomerA, il risultato è 31. Il totale delle vendite per località è 12,75 per Anversa e 18,25 per Bruxelles, anche se i dati sono per lo stesso cliente. Usando SCDType 2, possiamo analizzare i nostri dati con attributi storici.,
Metodi di implementazione
Esistono diversi metodi per caricare una dimensione che cambia lentamente di tipo 2 ina data warehouse. È possibile optare per un approccio T-SQL puro, con istruzioni multipleT-SQL o utilizzando l’istruzione MERGE. Quest’ultimo è spiegato neltipusando l’istruzione SQL Server MERGE per elaborare il tipo 2 Cambiando lentamente le dimensioni.
Con SSIS, è possibile utilizzare il built-in Lentamente cambiando dimensione guidata, che canhandle più scenari., Questa procedura guidata è descritta in tipsLoading dati storici in un Data Warehouse di SQL Server andHandle Lentamente cambiando dimensioni in SQL Server Integration Services. Il downsideof questa procedura guidata è prestazioni: utilizza il comando OLE DB per everyupdate, che può causare scarse prestazioni per i set di dati più grandi. Se si apportano modifiche al flusso di dati per risolvere questi problemi, non è possibile eseguire nuovamente la procedura guidata in quanto si perderebbero tutte le modifiche.
L’ultima opzione – a parte l’utilizzo di componenti 3rdparty – sta costruendo la logica SCD Type 2 da soli nel flusso di dati,che descriveremo nella prossima sezione.,
Implementazione in SSIS
La soluzione proposta in questo suggerimento funziona per qualsiasi versione di SSIS. Riprenderemo l’esempio della dimensione cliente, ma è stato aggiunto un campo aggiuntivo:l’attributo email. Non conserviamo la cronologia degli indirizzi e-mail, quindi anynew value sovrascriverà tutti gli altri valori.
In primo luogo, leggiamo i dati da una fonte, molto probabilmente un ambiente di staging. Quando si utilizza una sorgente relazionale, è possibile utilizzare il componente di origine OLE DB con una query SQL per leggere i dati. Seleziona solo le colonne di cui hai effettivamente bisogno per la tua dimensione. Il campo Validfrom viene calcolato anche qui., Dal momento che typicallyload dati dal giorno precedente, ValidFrom è impostato sulla data di ieri. Se non hai un’origine relazionale, puoi aggiungere questa colonna usando una Columntransformation derivata.
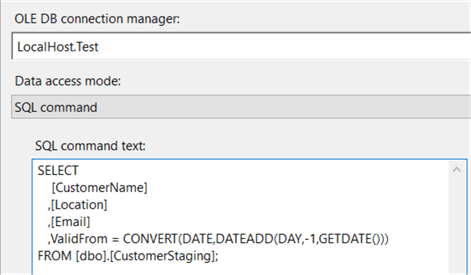
Nel passaggio successivo, stiamo facendo una ricerca contro la dimensione.Qui verificheremo se le righe in arrivo sono un inserto o un aggiornamento.Se non viene trovata alcuna corrispondenza, la riga è un nuovo membro della dimensione e deve essere inserita.Se viene trovata una corrispondenza, il membro della dimensione esiste già e dovremo verificare le modifiche di tipo SCD 2., A meno che tu non abbia una dimensione molto grande, puoi usarela cache completa:
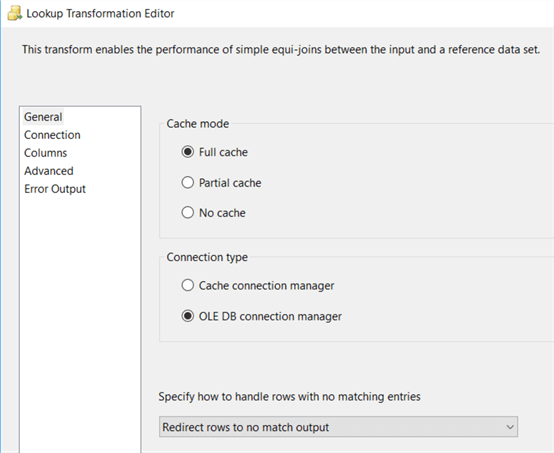
Configura la trasformazione di ricerca per inviare righe non corrispondenti all’output senza corrispondenza. In SSIS 2005 questa opzione non esiste ancora, quindi è possibile utilizzare l’output dell’errore o impostare la trasformazione in modo da ignorare gli errori e dividere gli inserti e gli aggiornamenti utilizzando una divisione condizionale.
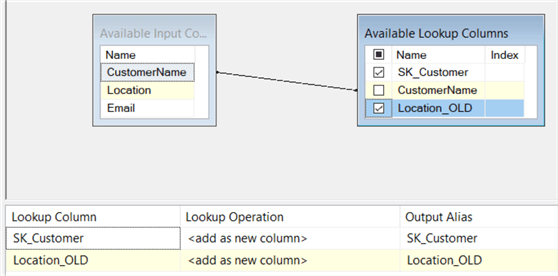
Nel riquadro di connessione, la seguente query SQL recupera le colonne surrogatekey, business key (CustomerName) e SCD Type 2., Per ogni membro,viene recuperata solo la riga più recente, filtrando nel campo ValidTo.
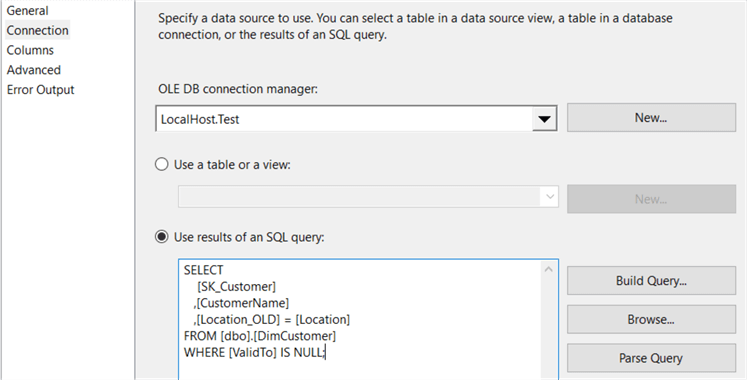
Il campo Posizione viene rinominato in Location_OLD per chiarezza. Nel riquadro Colonne, corrisponde alla chiave aziendale e seleziona tutte le altre colonne.
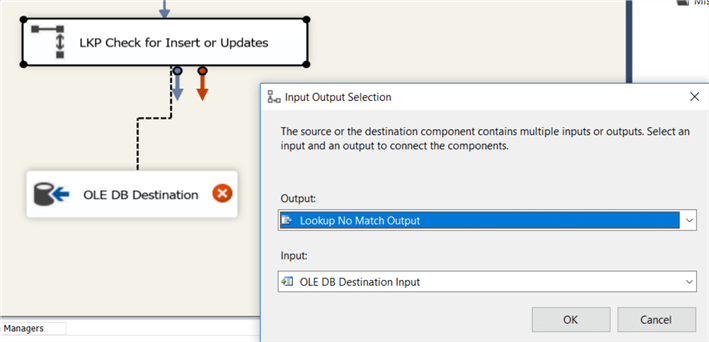
Ora possiamo aggiungere una destinazione OLE DB sulla tela. Questa destinazione scriverà tutte le nuove righe nella dimensione. Collegare l’output di ricerca senza corrispondenzadella trasformazione di ricerca alla destinazione.,
Nel riquadro di mappatura, mappare le colonne del flusso di dati con le colonne della tabella delle dimensioni.
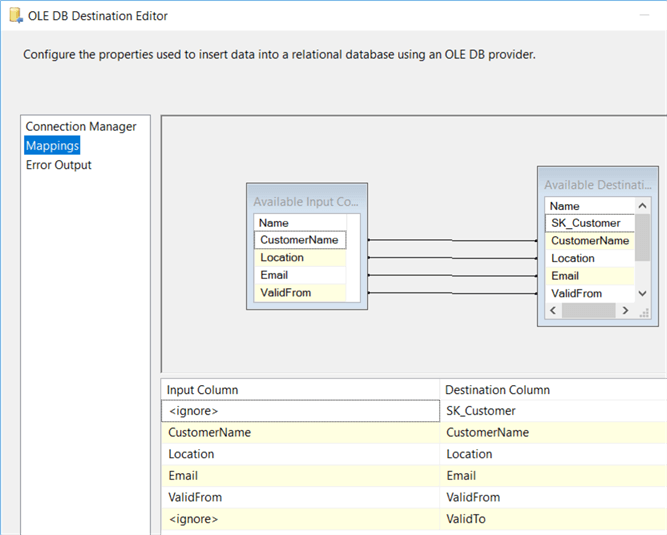
La colonna SK_Customer non è mappata, in quanto è una colonna di identitàe i suoi valori sono generati dal motore di database. Anche la colonna ValidTo è lasciata vuota. Le nuove righe non hanno valore per questa colonna.
Nella parte 2 di questo suggerimento continueremo la nostra configurazione del flusso di dati,dove controlleremo se una riga è un aggiornamento di tipo 2 o meno.,
Prossimi Passi
- Se vuoi sapere di più su di attuazione lentamente cambiando dimensioni inSSIS, è possibile controllare i seguenti suggerimenti:
- Utilizzo di SQL Server MERGE Istruzione per Tipo di Processo 2 Lentamente Cambiando Dimensioni
- Caricamento Storico dei Dati in un Data Warehouse SQL Server
- Maniglia Lentamente Cambiando Dimensioni in SQL Server Integration Services
- È possibile trovare ulteriori SSIS suggerimenti per lo sviluppo in questa panoramica.,
Ultimo Aggiornamento: 2018-08-09


Circa l’autore
 Koen Verbeeck è un BI professionale, specializzata nella business intelligence di Microsoft stack con un particolare amore per la SSIS.
Koen Verbeeck è un BI professionale, specializzata nella business intelligence di Microsoft stack con un particolare amore per la SSIS.Visualizza tutti i miei consigli