
Cos’è Recovery Point Objective (RPO)
Recovery Point Objective (RPO) descrive un periodo di tempo in cui le operazioni di un’azienda devono essere ripristinate a seguito di un evento dirompente, ad esempio un attacco informatico, un disastro naturale o un errore di comunicazione.
È una parte importante del piano di ripristino di emergenza ed è in genere associato a Recovery Time Objective (RTO), il tempo massimo per ripristinare le funzioni critiche a seguito di un evento dirompente.,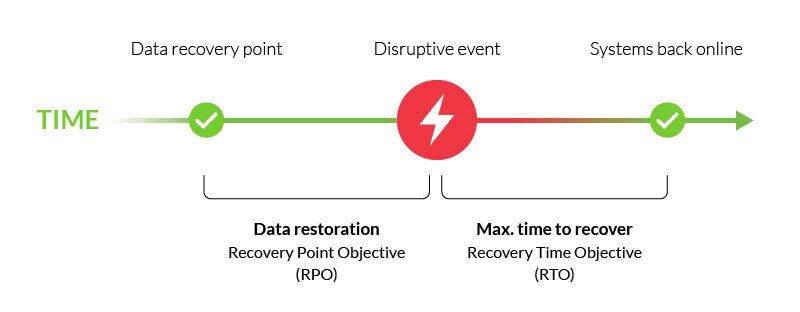
Ciascuno dei diversi processi aziendali, comprese le reti di comunicazione e l’infrastruttura, dovrebbe avere RPO unici, a seconda delle loro funzioni e importanza. Qui tratteremo come gli RPO per il recupero dei dati dovrebbero essere definiti in base alle esigenze di conformità e agli obiettivi aziendali.
Definizione degli RPO
In genere, gli RPO vengono impostati in base alla frequenza con cui i file vengono aggiornati. Ciò garantisce che, a seguito di un’interruzione del servizio, le operazioni ripristinate contengano la versione più aggiornata dei dati.,
Ad esempio, i file aggiornati di frequente richiedono un RPO breve (non più lungo di pochi minuti). Ciò significa che a seguito di un evento dirompente, le operazioni possono essere ripristinate con una perdita di dati minima.
I fattori che potrebbero influenzare i tuoi RPO includono:
- Industria – Le aziende che si occupano di informazioni altamente dinamiche o sensibili (ad esempio, cartelle cliniche o transazioni finanziarie) aggiornano i loro file più frequentemente rispetto a quelli che si occupano di file statici.
- Archiviazione dei dati-Come vengono memorizzati i dati (ad esempio, in appliance fisiche, nel cloud, ecc.,) può avere un impatto sulla velocità con cui può essere recuperato in seguito a un’interruzione del servizio.
- Considerazioni sulla conformità: numerosi schemi di conformità contengono clausole relative al disaster recovery e alla disponibilità dei dati. Ad esempio, la certificazione SOC 2 richiede un certo livello di disponibilità dei dati e integrità dell’elaborazione, che può influire sulla quantità accettabile di dati che possono essere persi a seguito di un’interruzione del servizio.
Una volta definiti, gli RPO dovrebbero diventare i capisaldi del piano di business continuity, fungendo da obiettivi per i dettagli dei processi it.,
Nel tuo piano, dovrebbero essere impostati diversi RPO per varie business unit. Ad esempio, un processo di dati mission critical, come le transazioni finanziarie, richiede un RPO più breve rispetto ai file aggiornati meno frequentemente, come i record dei dipendenti.
Di seguito sono riportati i livelli di esempio che è possibile utilizzare quando si impostano gli RPO richiesti per le unità aziendali:
0-1 ora
Si tratta di operazioni critiche che non possono permettersi di perdere più di un’ora di dati., Le transazioni commerciali e di dati sono di solito più elevate in volume e più dinamiche, rendendo spesso impossibile la loro ricreazione a causa del numero di variabili coinvolte.
Esempi di questo livello includono le transazioni bancarie, il sistema CRM e le cartelle cliniche dei pazienti.
1-4 ore
Le business unit che possono permettersi perdite di dati fino a quattro ore sono di natura semi-critica. Gli esempi includono log delle chat dei clienti e file server.
4-12 ore
Le unità aziendali che rientrano in questa categoria non possono tollerare di perdere più di 12 ore di informazioni., Gli esempi includono dati di marketing e vendite.
13-24 ore
Le business unit che compongono questa categoria gestiscono dati semi-importanti e richiedono un RPO che risale a un massimo di 24 ore. Ciò può includere i reparti risorse umane e acquisti, che aggiornano i dati meno frequentemente rispetto ai settori in uscita di un’azienda.
Failover e RPO
Il failover è il processo di commutazione tra il sistema primario e il sistema di backup durante un evento di interruzione o un downtime del sistema pianificato (ad esempio, manutenzione ordinaria).,
Quando si sceglie una soluzione di failover, è importante considerare gli RPO dell’organizzazione per evitare di perdere una quantità inaccettabile di dati quando si passa a un server di backup.
Ad esempio, un RPO di dieci minuti significa che la soluzione di failover deve rispondere entro tale lasso di tempo per assicurarsi di perdere non più di dieci minuti di dati.
I metodi di failover includono:
- Servizi DNS: un servizio DNS instrada il traffico da una soluzione hardware a un data center esterno. Questo è utile per il recupero cross-data center, nel caso in cui un intero data center va giù., Questo processo, tuttavia, presenta una serie di potenziali aspetti negativi, tra cui ritardi TTL correlati e degrado del servizio, che potrebbero aumentare i tempi di recupero dei dati.Inoltre, il processo di routing potrebbe rendere il failover irregolare, poiché gli ISP potrebbero continuare a instradare il traffico al server sbagliato fino a quando la cache DNS non viene aggiornata.
- Soluzioni hardware-Apparecchi fisici sono tenuti in loco. Nel caso in cui uno va giù, il traffico viene reindirizzato automaticamente a un server di backup.Questa soluzione non presenta problemi di latenza associati al failover DNS., Tuttavia, richiede l’hosting del sito di backup nella stessa posizione fisica del server di origine. Questa è generalmente considerata una cattiva pratica, in quanto espone il sito di backup a molte delle minacce che potrebbero influire sul cluster del server principale (ad esempio, guasti alla rete elettrica locale o disastri naturali).
- Servizi on-edge-Il failover è gestito off-site da una terza parte, dove i dati possono essere instradati senza problemi durante un evento dirompente., Il failover on-edge sfrutta al meglio sia le soluzioni DNS che quelle basate su hardware: non ci sono ritardi legati al TTL o costi aggiuntivi associati alla manutenzione delle appliance fisiche. Ciò garantisce una perdita di dati minima, consentendo di mantenere i tuoi obiettivi RPO.
Scopri come Imperva Site Failover può aiutarti con l’alta disponibilità .
Raggiungere gli obiettivi del punto di ripristino con Imperva
Imperva offre un servizio all’avanguardia che fornisce soluzioni di sicurezza, prestazioni e disponibilità per siti web e applicazioni web.,
La funzionalità di failover che offriamo consente ai nostri clienti di spostare il loro traffico su un sito di backup in pochi secondi, sia esso un server locale secondario o un data center posizionato dall’altra parte del mondo. Ciò garantisce funzionalità continue a seguito di un evento dirompente, consentendo di impostare e mantenere RPO aggressivi senza doversi preoccupare di ritardi relativi a TTL o manutenzione e sicurezza dell’appliance.,
Il nostro servizio di failover è arricchito da altre funzionalità ad alta disponibilità, tra cui una piattaforma CDN globale ad alta capacità, una suite completa di soluzioni di mitigazione DDoS e un sistema di bilanciamento del carico a livello di applicazione.