

In questo articolo, potrete conoscere SVM o Macchina di Vettore di Sostegno, che è uno dei più diffusi algoritmi di intelligenza artificiale (è uno dei top 10 algoritmi di intelligenza artificiale) e circa il Kernel Trucco, che si occupa di non linearità e di dimensioni maggiori., Toccheremo argomenti come iperpiani, moltiplicatori di Lagrange, avremo esempi visivi ed esempi di codice (simili all’esempio di codice usato nel capitolo KNN) per capire meglio questo algoritmo molto importante.
SVM Explained
La macchina vettoriale di supporto è un algoritmo di apprendimento supervisionato utilizzato principalmente per la classificazione ma può essere utilizzato anche per la regressione. L’idea principale è che sulla base dei dati etichettati (dati di allenamento) l’algoritmo cerca di trovare l’iperpiano ottimale che può essere utilizzato per classificare nuovi punti dati. In due dimensioni l’iperpiano è una linea semplice.,
Di solito un algoritmo di apprendimento cerca di apprendere le caratteristiche più comuni (ciò che differenzia una classe da un’altra) di una classe e la classificazione si basa su quelle caratteristiche rappresentative apprese (quindi la classificazione si basa sulle differenze tra le classi). L’SVM funziona al contrario. Trova gli esempi più simili tra le classi. Quelli saranno i vettori di supporto.
Ad esempio, consideriamo due classi, mele e limoni.,
Altri algoritmi impareranno le caratteristiche più evidenti e rappresentative di mele e limoni, come le mele sono verdi e arrotondate mentre i limoni sono gialli e hanno forma ellittica.
Al contrario, SVM cercherà mele molto simili ai limoni, ad esempio mele gialle e di forma ellittica. Questo sarà un vettore di supporto. L’altro vettore di supporto sarà un limone simile a una mela (verde e arrotondato). Quindi altri algoritmi imparano le differenze mentre SVM impara le somiglianze.,
Se visualizziamo l’esempio di cui sopra in 2D, ci sarà qualcosa di simile a questo:

Come si va da sinistra a destra, tutti gli esempi saranno classificati come mele, fino a raggiungere la mela gialla. Da questo punto, la fiducia che un nuovo esempio è una mela scende mentre la fiducia di classe limone aumenta., Quando la confidenza della classe limone diventa maggiore della confidenza della classe mela, i nuovi esempi saranno classificati come limoni (da qualche parte tra la mela gialla e il limone verde).
Sulla base di questi vettori di supporto, l’algoritmo cerca di trovare il miglior iperpiano che separa le classi. Nel 2D il hyperplane è una linea, quindi, sarebbe simile a questa:

Ok, ma perché non posso disegnare il blu di confine, come nella foto sopra?, Potrei anche disegnare i confini di simile a questo:

Come si può vedere, abbiamo un numero infinito di possibilità di disegnare la decisione di confine. Quindi, come possiamo trovare quello ottimale?
Trovare l’iperpiano ottimale
Intuitivamente la linea migliore è la linea che è lontana sia dagli esempi di mela che di limone (ha il margine più ampio)., Per avere una soluzione ottimale, dobbiamo massimizzare il margine in entrambi i modi (se abbiamo più classi, dobbiamo massimizzarlo considerando ciascuna delle classi).

Quindi, se si confronta l’immagine di cui sopra con l’immagine qui sotto, si può facilmente osservare, che il primo è ottimale hyperplane (linea) e la seconda è una soluzione sub-ottima, perché il margine è molto più breve.,

Perché vogliamo massimizzare i margini di prendere in considerazione tutte le classi, invece di utilizzare un margine per ogni classe, si utilizza un “globale” di margine, che prende in considerazione tutte le classi., Questo margine, ecco come sarebbe la linea viola nell’immagine seguente:

Questo margine è ortogonale al limite di distanza per il sostegno vettori.
Quindi dove abbiamo i vettori? Ciascuno dei calcoli (calcolare la distanza e gli iperpiani ottimali) sono fatti nello spazio vettoriale, quindi ogni punto dati è considerato un vettore. La dimensione dello spazio è definita dal numero di attributi degli esempi., Per capire la matematica dietro, si prega di leggere questa breve descrizione matematica di vettori, iperpiani e ottimizzazioni: SVM Succintamente.
Tutto sommato, i vettori di supporto sono punti dati che definiscono la posizione e il margine dell’iperpiano. Li chiamiamo vettori” di supporto”, perché questi sono i punti dati rappresentativi delle classi, se spostiamo uno di essi, la posizione e/o il margine cambieranno. Lo spostamento di altri punti dati non avrà effetto sul margine o sulla posizione dell’iperpiano.,
Per fare classificazioni, non abbiamo bisogno di tutti i punti dati di allenamento (come nel caso di KNN), dobbiamo salvare solo i vettori di supporto. Nel peggiore dei casi tutti i punti saranno vettori di supporto, ma questo è molto raro e se succede, dovresti controllare il tuo modello per errori o bug.
Quindi fondamentalmente l’apprendimento è equivalente a trovare l’hyperplane con il miglior margine, quindi è un semplice problema di ottimizzazione.,/h2>
I passi base della SVM sono:
- selezionare due iperpiani (in 2D), che separa i dati senza i punti tra di loro (linee rosse)
- massimizzare la loro distanza (il margine)
- la linea media (qui la linea a metà strada tra le due linee rosse) sarà la decisione di confine
Questo è molto bello e facile, ma trovare il miglior margine, il problema di ottimizzazione non è banale (è facile in 2D, quando ci sono solo due attributi, ma cosa succede se abbiamo N dimensioni con N molto grande numero)
Per risolvere il problema di ottimizzazione, utilizziamo i Moltiplicatori di Lagrange., Per capire questa tecnica è possibile leggere i seguenti due articoli: Dualità Langrange moltiplicatore e Una semplice spiegazione del perché Langrange moltiplicatori Wroks.
Fino ad ora avevamo dati separabili linearmente, quindi potevamo usare una linea come limite di classe. Ma cosa succede se abbiamo a che fare con set di dati non lineari?,
SVM for Non-Linear Set di Dati
Un esempio di non-lineare dei dati è:
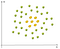
In questo caso non si può trovare una linea retta per separare le mele, limoni. Quindi, come possiamo risolvere questo problema. Useremo il trucco del kernel!
L’idea di base è che quando un set di dati è inseparabile nelle dimensioni correnti, aggiungi un’altra dimensione, forse in questo modo i dati saranno separabili., Pensaci, l’esempio sopra è in 2D ed è inseparabile, ma forse in 3D c’è uno spazio tra le mele e i limoni, forse c’è una differenza di livello, quindi i limoni sono al livello uno e i limoni sono al livello due. In questo caso possiamo facilmente disegnare un iperpiano di separazione (in 3D un iperpiano è un piano) tra il livello 1 e 2.
Mapping to Higher Dimensions
Per risolvere questo problema non dovremmo semplicemente aggiungere ciecamente un’altra dimensione, dovremmo trasformare lo spazio in modo da generare intenzionalmente questa differenza di livello.,
Mappatura da 2D a 3D
Supponiamo di aggiungere un’altra dimensione chiamata X3. Un’altra trasformazione importante è che nella nuova dimensione i punti sono organizzati usando questa formula x12 + x22.
Se riportiamo il piano definito dagli x2 + y2 formula, si ottiene qualcosa di simile a questo:

Ora dobbiamo mappa le mele e limoni (che sono solo semplici punti) per questo nuovo spazio. Pensaci attentamente, cosa abbiamo fatto?, Abbiamo appena usato una trasformazione in cui abbiamo aggiunto livelli in base alla distanza. Se sei nell’origine, i punti saranno al livello più basso. Mentre ci allontaniamo dall’origine, significa che stiamo salendo la collina (spostandoci dal centro del piano verso i margini), quindi il livello dei punti sarà più alto., Ora, se consideriamo che l’origine è il limone dal centro, avremo qualcosa di simile a questo:
Ora si può facilmente separare le due classi. Queste trasformazioni sono chiamate kernel. I kernel più diffusi sono: Kernel polinomiale, Kernel gaussiano, Funzione base radiale (RBF), Kernel RBF di Laplace, Kernel Sigmoid, Kernel RBF di Anove, ecc. (vedi Funzioni del kernel o una descrizione più dettagliata dei kernel di apprendimento automatico).,
la Mappatura da 1D 2D
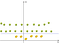
un Altro, più semplice esempio in 2D sarebbe:

Dopo l’utilizzo il kernel e dopo tutte le trasformazioni avremo:

Così, dopo la trasformazione, siamo facilmente in grado di delimitare le due classi, utilizzando solo una singola linea.,
Nelle applicazioni reali non avremo una semplice linea retta, ma avremo molte curve e dimensioni elevate. In alcuni casi non avremo due iperpiani che separano i dati senza punti tra di loro, quindi abbiamo bisogno di alcuni compromessi, tolleranza per valori anomali. Fortunatamente l’algoritmo SVM ha un cosiddetto parametro di regolarizzazione per configurare il trade-off e tollerare valori anomali.
Parametri di ottimizzazione
Come abbiamo visto nella sezione precedente scegliere il kernel giusto è fondamentale, perché se la trasformazione non è corretta, allora il modello può avere risultati molto scarsi., Come regola generale, controlla sempre se hai dati lineari e in tal caso usa sempre SVM lineare (kernel lineare). SVM lineare è un modello parametrico, ma un SVM del kernel RBF non lo è, quindi la complessità di quest’ultimo cresce con la dimensione del set di allenamento. Non solo è più costoso addestrare un SVM del kernel RBF, ma è anche necessario mantenere la matrice del kernel in giro, e la proiezione in questo spazio dimensionale “infinito” più alto in cui i dati diventano separabili linearmente è più costosa anche durante la previsione., Inoltre, hai più iperparametri da sintonizzare, quindi anche la selezione del modello è più costosa! E infine, è molto più facile adattarsi eccessivamente a un modello complesso!
Regolarizzazione
Il parametro di regolarizzazione (in python si chiama C) indica all’ottimizzazione SVM quanto si vuole evitare di perdere la classificazione di ogni esempio di allenamento.
Se il C è più alto, l’ottimizzazione sceglierà più piccolo margine hyperplane, in modo da dati di formazione perdere tasso di classificazione sarà inferiore.,
D’altra parte, se il C è basso, il margine sarà grande, anche se ci saranno esempi di dati di allenamento classificati. Questo è illustrato nei seguenti due schemi:

Come si può vedere nell’immagine, quando C è basso, il margine è superiore (quindi implicitamente non abbiamo così tante curve, la linea non segue strettamente i punti di dati), anche se due mele sono stati classificati come limoni., Quando la C è alta, il confine è pieno di curve e tutti i dati di allenamento sono stati classificati correttamente. Non dimenticare, anche se tutti i dati di allenamento sono stati classificati correttamente, questo non significa che l’aumento della C aumenterà sempre la precisione (a causa dell’overfitting).
Gamma
Il prossimo parametro importante è Gamma. Il parametro gamma definisce fino a che punto raggiunge l’influenza di un singolo esempio di allenamento. Ciò significa che la Gamma alta considererà solo punti vicini all’iperpiano plausibile e la gamma bassa considererà punti a maggiore distanza.,

Come si può vedere, diminuendo la Gamma di risultati che di trovare il giusto hyperplane prenderà in considerazione i punti a distanze maggiori, in modo più e più punti verranno utilizzati (linee verdi), indica che i punti sono stati considerati quando trovare l’ottimale hyperplane).
Margine
L’ultimo parametro è il margine. Abbiamo già parlato di margine, margine più alto risultati modello migliore, quindi una migliore classificazione (o previsione)., Il margine dovrebbe essere sempre massimizzato.
SVM Esempio utilizzando Python
In questo esempio useremo il Social_Networks_Ads.file csv, lo stesso file che abbiamo usato nell’articolo precedente, vedere KNN esempio utilizzando Python.
In questo esempio scriverò solo le differenze tra SVM e KNN, perché non voglio ripetermi in ogni articolo! Se vuoi l’intera spiegazione su come possiamo leggere il set di dati, come analizziamo e dividiamo i nostri dati o come possiamo valutare o tracciare i confini delle decisioni, leggi l’esempio di codice del capitolo precedente (KNN)!,
Poiché la libreria sklearn è una libreria Python molto ben scritta e utile, non abbiamo troppo codice da cambiare. L’unica differenza è che dobbiamo importare la classe SVC (SVC = SVM in sklearn) da sklearn.svm invece della classe KNeighborsClassifier di sklearn.vicino.
Dopo aver importato l’SVC, possiamo creare il nostro nuovo modello utilizzando il costruttore predefinito. Questo costruttore ha molti parametri, ma descriverò solo quelli più importanti, il più delle volte non userai altri parametri.,
I parametri più importanti sono:
- kernel: il tipo di kernel da utilizzare. I kernel più comuni sono rbf (questo è il valore predefinito), poly o sigmoid, ma puoi anche creare il tuo kernel.,
- C: questo è il parametro di regolarizzazione descritto per la messa a punto dei Parametri di sezione
- gamma: questo è stato descritto anche nella regolazione dei Parametri della sezione
- grado: viene utilizzato solo se il kernel è il poli e stabilisce il grado di polinom
- probabilità: questo è un parametro booleano e se è vero, allora il modello tornerà per ogni stima, il vettore di probabilità di appartenenza a ciascuna classe della variabile di risposta. Quindi in pratica ti darà le confidenze per ogni previsione.,
- shrinking: questo mostra se si desidera o meno un’euristica di restringimento utilizzata nell’ottimizzazione dell’SVM, che viene utilizzata nell’ottimizzazione minima sequenziale. Il suo valore predefinito è true, e se non hai una buona ragione, per favore non cambiare questo valore in false, perché il restringimento migliorerà notevolmente le tue prestazioni, per una minima perdita in termini di precisione nella maggior parte dei casi.
Ora vediamo l’output dell’esecuzione di questo codice., La decisione di confine per il training set assomiglia a questo:

Come si può vedere e come abbiamo imparato per la messa a punto dei Parametri di sezione, perché C è un piccolo valore (0.1) la decisione di contorno è liscio.
Ora se aumentiamo la C da 0.,Da 1 a 100 avremo più curve nella decisione di confine:

che Cosa accadrebbe se abbiamo C=0,1 ma ora dobbiamo aumentare la Gamma da 0,1 a 10? Vediamo!

che Cosa è successo qui? Perché abbiamo un modello così cattivo?, Come hai visto nella sezione Parametri di sintonizzazione, gamma alta significa che quando si calcola l’iperpiano plausibile consideriamo solo i punti che sono vicini. Ora, poiché la densità dei punti verdi è alta solo nella regione verde selezionata, in quella regione i punti sono abbastanza vicini all’iperpiano plausibile, quindi sono stati scelti quegli iperpiani. Fai attenzione al parametro gamma, perché questo può avere un’influenza molto negativa sui risultati del tuo modello se lo imposti su un valore molto alto (ciò che è un “valore molto alto” dipende dalla densità dei punti dati).,
Per questo esempio i valori migliori per C e Gamma sono 1.0 e 1.0. Ora, se si esegue il modello sul set di test si ottiene il seguente diagramma:

E la Confusione Matrice simile a questo:

Come si può vedere, abbiamo solo 3 Falsi Positivi e solo 4 i Falsi Negativi., La precisione di questo modello è del 93% che è un ottimo risultato, abbiamo ottenuto un punteggio migliore rispetto all’utilizzo di KNN (che aveva una precisione dell ‘ 80%).
NOTA: la precisione non è l’unica metrica utilizzata in ML e inoltre non è la migliore metrica per valutare un modello, a causa del paradosso dell’accuratezza. Usiamo questa metrica per semplicità, ma più avanti, nel capitolo Metriche per valutare gli algoritmi AI parleremo del paradosso dell’accuratezza e mostrerò altre metriche molto popolari utilizzate in questo campo.,
Conclusioni
In questo articolo abbiamo visto un algoritmo di apprendimento supervisionato molto popolare e potente, la Support Vector Machine. Abbiamo imparato l’idea di base, cos’è un iperpiano, quali sono i vettori di supporto e perché sono così importanti. Abbiamo anche visto molte rappresentazioni visive, che ci hanno aiutato a capire meglio tutti i concetti.
Un altro argomento importante che abbiamo toccato è il trucco del kernel, che ci ha aiutato a risolvere problemi non lineari.
Per avere un modello migliore, abbiamo visto tecniche per sintonizzare l’algoritmo., Alla fine dell’articolo abbiamo avuto un esempio di codice in Python, che ci ha mostrato come possiamo usare l’algoritmo KNN.
Come considerazioni finali, vorrei dare alcuni pro& cons e alcuni casi d’uso popolari.,
Pro
- SVN può essere molto efficiente, perché utilizza solo un sottoinsieme dei dati di allenamento, solo il supporto vettori
- Funziona molto bene su piccoli insiemi di dati, sulla non-lineare insiemi di dati e di alta spazi di dimensione
- È molto efficace nei casi in cui il numero di dimensioni è maggiore del numero di campioni
- Si può avere un’alta precisione, a volte può eseguire anche meglio di reti neurali
- Non molto sensibile per l’overfitting
Svantaggi
- tempo di Formazione è alta quando abbiamo grandi insiemi di dati
- Quando il set di dati è più rumore (ho.,e. le classi target si sovrappongono) SVM non funziona bene
Casi d’uso popolari
- Classificazione del testo
- Rilevamento dello spam
- Sentiment analysis
- Aspect-based recognition
- Aspect-based recognition
- Handwritten digit recognition