
ce este obiectivul punctului de recuperare (RPO)
obiectivul punctului de recuperare (RPO) descrie o perioadă de timp în care operațiunile unei întreprinderi trebuie restabilite în urma unui eveniment perturbator, de exemplu, un atac cibernetic, un dezastru natural sau o defecțiune a comunicațiilor.
este o parte importantă de disaster recovery plan, și este de obicei asociat cu timp de recuperare (RTO)—timpul maxim pentru a restabili funcțiile critice în urma unui eveniment perturbator.,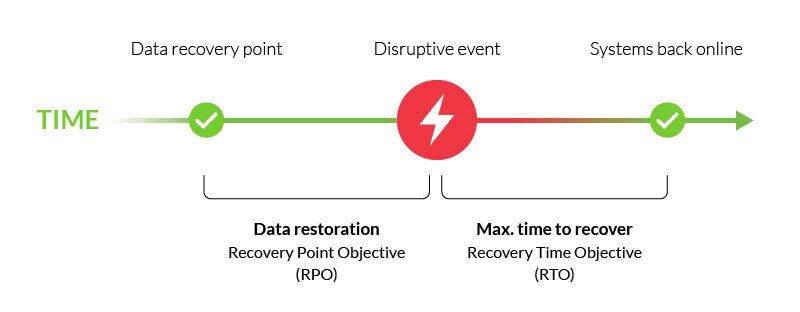
Fiecare dintre întreprinderii procese diferite, inclusiv rețelele de comunicații și a infrastructurii ar trebui să aibă unic RPOs, în funcție de funcțiile lor și importanță. Aici vom acoperi modul în care RPO-urile pentru recuperarea datelor ar trebui definite în funcție de nevoile dvs. de Conformitate și de obiectivele de afaceri.
definirea RPO-urilor
De obicei, RPO-urile sunt setate în funcție de frecvența cu care sunt actualizate fișierele. Acest lucru asigură că, în urma unei întreruperi a serviciului, operațiunile restaurate conțin cea mai recentă versiune a datelor.,de exemplu, fișierele actualizate frecvent necesită un RPO scurt (nu mai mult de câteva minute). Aceasta înseamnă că, în urma unui eveniment perturbator, operațiunile pot fi restaurate cu pierderi minime de date.
factorii care ar putea influența RPO – urile dvs. includ:
- Industrie-întreprinderile care se ocupă de informații extrem de dinamice sau sensibile (de exemplu, înregistrări medicale sau tranzacții financiare) își actualizează fișierele mai frecvent decât cele care se ocupă de fișiere statice.
- stocarea datelor – modul în care sunt stocate datele dvs. (de exemplu, în aparatele fizice, în cloud etc.) – ,) poate afecta cât de repede poate fi recuperat în urma unei întreruperi a serviciului.
- considerații de conformitate – numeroase scheme de conformitate conțin clauze care se referă la recuperarea în caz de dezastru și disponibilitatea datelor. De exemplu, certificarea SOC 2 necesită un anumit nivel de disponibilitate a datelor și de integritate a procesării, ceea ce poate avea un impact asupra cantității acceptabile de date care pot fi pierdute în urma unei întreruperi a serviciului.odată definite, RPO-urile ar trebui să devină pietrele de temelie ale planului dvs. de continuitate a afacerii, servind ca obiective pentru detaliile proceselor it.,
în planul dvs., ar trebui să fie setate diferite RPO pentru diferite unități de afaceri. De exemplu, un proces de date critice pentru misiune, cum ar fi tranzacțiile financiare, are nevoie de un RPO mai scurt decât fișierele actualizate mai puțin frecvent, cum ar fi înregistrările angajaților.
următoarele sunt exemple de niveluri pe care le puteți utiliza atunci când setați RPO-urile necesare pentru unitățile dvs. de afaceri:
0-1 oră
acestea sunt operațiuni critice care nu își pot permite să piardă mai mult de o oră de date., Tranzacțiile de afaceri și de date sunt de obicei mai mari în volum și mai dinamice, ceea ce face ca recrearea lor să fie adesea imposibilă din cauza numărului de variabile implicate.
Exemple de acest nivel includ tranzacții bancare, sistemul CRM, și înregistrările pacientului.unitățile de afaceri care pot permite pierderi de date de până la patru ore sunt de natură semi-critică. Exemplele includ jurnalele de chat ale clienților și serverele de fișiere.unitățile de afaceri care se încadrează în această categorie nu pot tolera pierderea a mai mult de 12 ore de informații., Exemplele includ date de marketing și vânzări.
13-24 ore
unitățile de afaceri care cuprind această categorie se ocupe de date semi-importante, și necesită un RPO care merge înapoi un maxim de 24 de ore. Aceasta poate include departamentele de resurse umane și achiziții, care actualizează datele mai rar decât sectoarele de ieșire ale unei afaceri.
Failover și RPO
Failover este procesul de comutare între primar și sisteme de rezervă în timpul unui eveniment perturbator sau planificate de nefuncționare a sistemului (de exemplu, de întreținere de rutină).,
atunci când alegeți o soluție de eșec, este important să luați în considerare RPO-urile organizației dvs. pentru a evita pierderea unei cantități inacceptabile de date atunci când treceți la un server de rezervă.
de exemplu, un RPO de zece minute înseamnă că soluția dvs. de failover trebuie să răspundă în acel interval de timp pentru a vă asigura că nu pierdeți mai mult de zece minute de date.
metodele de Failover includ:
- servicii DNS-un serviciu DNS rutează traficul de la o soluție hardware la un centru de date în afara site-ului. Acest lucru este util pentru recuperare cross-data center, în cazul în care un întreg centru de date se duce în jos., Cu toate acestea, acest proces are o serie de dezavantaje potențiale, inclusiv întârzierile legate de TTL și degradarea serviciilor, ceea ce ar putea crește timpul de recuperare a datelor.În plus, procesul de rutare ar putea face failover inegale, ca ISP-uri ar putea continua rutare de trafic la serverul greșit până când cache-ul lor DNS este actualizat.
- soluții Hardware-aparatele fizice sunt păstrate la fața locului. În cazul în care unul coboară, traficul este redirecționat automat către un server de rezervă.Această soluție nu are niciuna dintre problemele de latență asociate cu eșecul DNS., Cu toate acestea, necesită găzduirea site-ului dvs. de rezervă în aceeași locație fizică ca și serverul dvs. de origine. Aceasta este în general considerată o practică proastă, deoarece expune site-ul de rezervă la multe dintre amenințările care ar avea impact asupra clusterului serverului principal (de exemplu, defectarea rețelei electrice locale sau dezastre naturale).
- servicii On-edge-Failover este gestionat în afara site-ului de către o terță parte, unde datele pot fi dirijate fără probleme în timpul unui eveniment perturbator., Failover On-edge ia cele mai bune soluții DNS și bazate pe hardware-nu există întârzieri legate de TTL sau costuri suplimentare asociate cu întreținerea aparatelor fizice. Acest lucru asigură pierderi minime de date, permițându-vă să vă mențineți obiectivele RPO.
vedeți cum Imperva site Failover vă poate ajuta cu disponibilitate ridicată .
îndeplinirea obiectivelor obiectivului punctului de recuperare cu Imperva
Imperva oferă un serviciu on-edge care oferă soluții de îmbunătățire a securității, performanței și disponibilității pentru site-uri web și aplicații web.,caracteristica failover pe care o oferim permite clienților noștri să își mute traficul pe un site de backup în câteva secunde, fie că este vorba de un server local secundar sau de un centru de date poziționat în cealaltă parte a lumii. Acest lucru asigură funcționalitatea continuă după un eveniment perturbator, permițându-vă să setați și să mențineți RPO-uri agresive fără a fi nevoie să vă faceți griji cu privire la întârzierile legate de TTL sau la întreținerea și securitatea aparatului.,serviciul nostru de failover este completat de alte caracteristici cu disponibilitate ridicată, inclusiv o platformă CDN globală de mare capacitate, o suită cuprinzătoare de soluții de atenuare DDoS și un balancer de încărcare în straturi de aplicații.