

În acest articol, veți învăța despre SVM sau Support Vector Machine, care este una dintre cele mai populare algoritmi AI (e unul de top 10 AI algoritmi) și despre Kernel Trick, care se ocupă cu non-liniaritate și dimensiuni mai mari., Vom atinge subiecte precum hyperplane, multiplicatori Lagrange, vom avea exemple vizuale și exemple de cod (similar cu exemplul de cod folosit în capitolul KNN) pentru a înțelege mai bine acest algoritm foarte important.
SVM Explained
mașina vector de suport este un algoritm de învățare supravegheat folosit mai ales pentru clasificare, dar poate fi folosit și pentru regresie. Ideea principală este că, pe baza datelor etichetate (date de antrenament), algoritmul încearcă să găsească hiperplanul optim care poate fi utilizat pentru a clasifica noi puncte de date. În două dimensiuni, hyperplanul este o linie simplă.,de obicei, un algoritm de învățare încearcă să învețe cele mai comune caracteristici (ce diferențiază o clasă de alta) ale unei clase, iar clasificarea se bazează pe acele caracteristici reprezentative învățate (deci clasificarea se bazează pe diferențele dintre clase). SVM funcționează invers. Găsește cele mai similare Exemple între clase. Aceștia vor fi vectorii de sprijin.de exemplu, să luăm în considerare două clase, mere și lămâi.,alți algoritmi vor învăța cele mai evidente, cele mai reprezentative caracteristici ale merelor și lămâilor, cum ar fi merele verzi și rotunjite, în timp ce lămâile sunt galbene și au formă eliptică.în schimb, SVM va căuta mere care sunt foarte asemănătoare cu lămâile, de exemplu mere care sunt galbene și au formă eliptică. Acesta va fi un vector de sprijin. Celălalt vector de sprijin va fi o lămâie similară cu un măr (verde și rotunjit). Deci, alți algoritmi învață diferențele în timp ce SVM învață asemănări.,
Dacă vom vizualiza exemplul de mai sus în 2D, vom avea ceva de genul asta:

Cum vom merge de la stânga la dreapta, toate exemplele vor fi clasificate ca mere până când vom ajunge la mere galbene. Din acest punct, încrederea că un nou exemplu este un măr scade în timp ce încrederea clasei de lămâie crește., Când încrederea clasei de lămâie devine mai mare decât încrederea clasei de mere, noile exemple vor fi clasificate ca lămâi (undeva între mărul galben și lămâia verde).pe baza acestor vectori de suport, algoritmul încearcă să găsească cel mai bun hyperplane care separă clasele. În 2D hiperplan este o linie, astfel încât acesta ar arata astfel:

Ok, dar de ce am desenat albastru limita ca în imaginea de mai sus?, Am putea desena, de asemenea, limitele de genul asta:

după Cum puteți vedea, avem un număr infinit de posibilități de a desena decizia de frontieră. Deci, cum îl putem găsi pe cel optim?
găsirea Hiperplanului optim
intuitiv cea mai bună linie este linia care este departe atât de exemplele de mere, cât și de lămâie (are cea mai mare marjă)., Pentru a avea o soluție optimă, trebuie să maximizăm Marja în ambele sensuri (dacă avem mai multe clase, atunci trebuie să o maximizăm luând în considerare fiecare dintre clase).

Deci, dacă vom compara imaginea de mai sus cu poza de mai jos, putem observa cu ușurință, că în primul rând este optimă hiperplan (linie) și cel de-al doilea este o soluție sub-optimă, deoarece marja este mult mai scurt.,

Pentru că vrem să maximiza marjele de a lua în considerare toate clasele, în loc de a folosi o marjă pentru fiecare clasă, vom folosi un „global” marjă, care ia în considerare toate clasele., Această marjă ar arata ca linia violet în imaginea de mai jos:

Această marjă este ortogonală a limita și echidistante pentru sprijinul vectori.deci ,unde avem vectori? Fiecare dintre calcule (calculați distanța și hiperplanele optime) se face în spațiul vectorial, astfel încât fiecare punct de date este considerat un vector. Dimensiunea spațiului este definită de numărul de atribute ale exemplelor., Pentru a înțelege matematica din spatele, vă rugăm să citiți această scurtă descriere matematică a vectorilor, hyperplanes și optimizări: SVM succint.în total, vectorii de suport sunt puncte de date care definesc poziția și marginea hyperplanului. Le numim vectori „suport”, deoarece acestea sunt punctele de date reprezentative ale claselor, dacă mutăm unul dintre ele, poziția și/sau marja se vor schimba. Mutarea altor puncte de date nu va avea efect asupra marjei sau poziției hyperplanului.,pentru a face clasificări, nu avem nevoie de toate punctele de date de antrenament (ca în cazul KNN), trebuie să salvăm doar vectorii de suport. În cel mai rău caz, toate punctele vor fi vectori de sprijin, dar acest lucru este foarte rar și dacă se întâmplă, atunci ar trebui să verificați modelul pentru erori sau erori.deci, practic, învățarea este echivalentă cu găsirea hyperplanului cu cea mai bună marjă, deci este o problemă simplă de optimizare.,/h2>
pașii De bază al SVM sunt:
- selectați două hyperplanes (în 2D), care separă datele fără puncte între ele (linii roșii)
- pentru a maximiza distanța lor (marja)
- linie de medie (aici linia jumătate de drum între cele două linii roșii) va fi decizia limita
Acest lucru este foarte frumos și ușor, dar găsirea celor mai bune marja, problema de optimizare nu este trivial (este ușor în 2D, atunci când avem doar două atribute, dar dacă avem N dimensiuni cu N un număr foarte mare)
Pentru a rezolva problema de optimizare, vom folosi Multiplicatorilor Lagrange., Pentru a intelege aceasta tehnica se poate citi în următoarele două articole: Dualitatea Langrange de Multiplicare și O Explicație de Ce Langrange Multiplicatori Wroks.până acum am avut date separabile liniar, așa că am putea folosi o linie ca limită de clasă. Dar dacă avem de-a face cu seturi de date neliniare?,
SVM pentru Non-Linear Seturi de Date
Un exemplu de non-linear de date este:
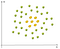
În acest caz nu putem găsi o linie dreaptă pentru a separa merele de lămâi. Deci, cum putem rezolva această problemă. Vom folosi trucul Kernel-ului!ideea de bază este că atunci când un set de date este inseparabil în dimensiunile curente, adăugați o altă dimensiune, poate că în acest fel datele vor fi separabile., Gândiți-vă, exemplul de mai sus este în 2D și este inseparabil, dar poate în 3D există un decalaj între mere și lămâi, poate există o diferență de nivel, deci lămâile sunt la nivelul unu și lămâile sunt la nivelul doi. În acest caz, putem desena cu ușurință un hyperplane de separare (în 3D un hyperplane este un plan) între nivelul 1 și 2.pentru a rezolva această problemă nu ar trebui să adăugăm orbește o altă dimensiune, ar trebui să transformăm spațiul astfel încât să generăm intenționat această diferență de nivel.,
maparea de la 2D la 3D
Să presupunem că adăugăm o altă dimensiune numită X3. O altă transformare importantă este că în noua dimensiune punctele sunt organizate folosind această formulă x12 + x22.
Dacă ne complot planul definit de către x2 + y2 formula, vom obține ceva de genul asta:

Acum trebuie să hartă mere și lămâi (care sunt doar simple puncte) în acest nou spațiu. Gândește-te bine, ce am făcut?, Tocmai am folosit o transformare în care am adăugat niveluri bazate pe distanță. Dacă vă aflați în origine, atunci punctele vor fi la cel mai scăzut nivel. Pe măsură ce ne îndepărtăm de origine, înseamnă că urcăm pe deal (deplasându-ne din centrul planului spre margini), astfel încât nivelul punctelor va fi mai mare., Acum, dacă avem în vedere că la origine este lamaie de la centru, vom avea ceva de genul asta:
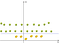
Acum putem separa cu ușurință cele două clase. Aceste transformări se numesc kernel-uri. Nucleele populare sunt: Kernel polinomial, Kernel Gaussian, funcția de bază radială (RBF), Kernel Laplace RBF, Kernel Sigmoid, Kernel Anove RBF etc. (vezi funcțiile kernelului sau o descriere mai detaliată a nucleelor de învățare automată).,
Cartografiere de la 1D la 2D
un Alt, mai ușor exemplu în 2D ar fi:

După utilizarea kernel-ul și după toate transformările vom obține:

Deci, după transformare, cu ușurință putem delimita două clase, folosind doar o singură linie.,în aplicațiile din viața reală nu vom avea o linie dreaptă simplă, dar vom avea o mulțime de curbe și dimensiuni mari. În unele cazuri nu vom avea două hyperplane care separă datele fără puncte între ele, așa că avem nevoie de unele compromisuri, toleranță pentru valori aberante. Din fericire, algoritmul SVM are un așa-numit parametru de regularizare pentru a configura compromisul și pentru a tolera valorile aberante.
parametrii de reglare
așa cum am văzut în secțiunea anterioară alegerea kernelului potrivit este crucială, deoarece dacă transformarea este incorectă, atunci modelul poate avea rezultate foarte slabe., De regulă, verificați întotdeauna dacă aveți date liniare și, în acest caz, utilizați întotdeauna SVM liniar (kernel liniar). SVM liniar este un model parametric, dar un SVM kernel RBF nu este, astfel încât complexitatea acestuia din urmă crește cu dimensiunea setului de antrenament. Nu numai că este mai scump să antrenezi un SVM de kernel RBF, dar trebuie să păstrezi matricea kernelului în jur, iar proiecția în acest spațiu dimensional „infinit”, unde datele devin separabile liniar, este mai scumpă și în timpul predicției., În plus, aveți mai multe hiperparametre pentru a regla, astfel încât selecția modelului este mai scumpă! Și, în sfârșit, este mult mai ușor să se suprapună un model complex!
regularizare
parametrul regularizare (în python se numește C) spune optimizarea SVM cât de mult doriți să evitați ratarea clasificării fiecărui exemplu de antrenament.
În cazul în care C este mai mare, optimizarea va alege hyperplane marjă mai mică, astfel încât rata de clasificare a datelor de formare dor va fi mai mică.,pe de altă parte, dacă C este scăzut, atunci marja va fi mare, chiar dacă vor exista Exemple de date de formare clasificate. Acest lucru este arătat în următoarele două diagrame:

după Cum puteți vedea în imagine, când C este scăzut, marja este mai mare (deci, implicit, nu avem atât de multe curbe, linia nu urmează cu strictețe puncte de date), chiar dacă două mere au fost clasificate ca lămâi., Când C este mare, limita este plină de curbe și toate datele de antrenament au fost clasificate corect. Nu uitați, chiar dacă toate datele de antrenament au fost clasificate corect, acest lucru nu înseamnă că creșterea C va crește întotdeauna precizia (din cauza suprasolicitării).
Gamma
următorul parametru important este Gamma. Parametrul gamma definește cât de departe ajunge influența unui singur exemplu de antrenament. Aceasta înseamnă că gama înaltă va lua în considerare doar punctele apropiate de hiperplanul plauzibil, iar gama scăzută va lua în considerare punctele la o distanță mai mare.,

după Cum puteți vedea, scăderea Gamma va rezulta că identificarea corectă a unui hiperplan va lua în considerare puncte la distanțe mai mari cu atât mai mult și mai multe puncte va fi folosit (liniile verzi indică ce puncte au fost luate în considerare atunci când găsirea hiperplan optim).
marja
ultimul parametru este marja. Am vorbit deja despre marja, rezultatele marjei mai mari model mai bun, astfel încât o mai bună clasificare (sau predicție)., Marja ar trebui să fie întotdeauna maximizată.
exemplu SVM folosind Python
În acest exemplu vom folosi Social_Networks_Ads.fișier csv, același fișier ca și cum am folosit în articolul precedent, a se vedea exemplul KNN folosind Python.în acest exemplu, voi scrie doar diferențele dintre SVM și KNN, pentru că nu vreau să mă repet în fiecare articol! Dacă doriți întreaga explicație despre cum putem citi setul de date, cum analizăm și împărțim datele noastre sau cum putem evalua sau trasa limitele deciziei, atunci vă rugăm să citiți exemplul de cod din capitolul precedent (KNN)!,deoarece biblioteca sklearn este o bibliotecă Python foarte bine scrisă și utilă, nu avem prea mult cod de schimbat. Singura diferență este că trebuie să importăm clasa SVC (SVC = SVM în sklearn) din sklearn.svm în loc de clasa KNeighborsClassifier din sklearn.vecinii.
după importul SVC, putem crea noul nostru model folosind constructorul predefinit. Acest constructor are mulți parametri, dar îi voi descrie doar pe cei mai importanți, de cele mai multe ori nu veți folosi alți parametri.,
cei mai importanți parametri sunt:
- kernel: tipul de kernel care va fi utilizat. Cele mai frecvente nuclee sunt rbf (aceasta este valoarea implicită), poly sau sigmoid, dar puteți crea și propriul kernel.,
- C: aceasta este regularizarea parametru descris în Parametrii de Tuning secțiunea
- gama: aceasta a fost, de asemenea, descrise în Parametrii de Tuning secțiunea
- grad: este utilizată numai dacă cel ales kernel este poli și stabilește gradul de polinom
- probabilitate: acesta este un parametru boolean și dacă e adevărat, atunci modelul va reveni pentru fiecare predicție, vectorul de probabilități de apartenență la fiecare categorie a variabilei de răspuns. Deci, practic, vă va oferi confidențele pentru fiecare predicție.,
- shrinking: aceasta arată dacă doriți sau nu o euristică în scădere utilizată în optimizarea SVM, care este utilizată în optimizarea minimă secvențială. Valoarea implicită este adevărată, dacă nu aveți un motiv bun, vă rugăm să nu schimbați această valoare în fals, deoarece scăderea vă va îmbunătăți considerabil performanța, pentru pierderi foarte mici în ceea ce privește precizia în majoritatea cazurilor.
acum vă permite să vedeți rezultatul de funcționare a acestui cod., Decizia limita pentru setul de antrenare se pare ca acest lucru:

după Cum putem vedea și cum am învățat în Parametrii de Tuning secțiune, deoarece C are o valoare mică (0.1) decizia limita este buna.
acum, dacă vom crește C de la 0.,De la 1 la 100, vom avea mai multe curbe în decizia de frontieră:

Ce s-ar întâmpla dacă am folosi C=0.1 dar acum vom crește Gama de la 0,1 la 10? Să vedem!

Ce s-a întâmplat aici? De ce avem un model atât de rău?, După cum ați văzut în secțiunea parametrilor de Tuning, high gamma înseamnă că atunci când calculăm hiperplanul plauzibil luăm în considerare doar punctele care sunt apropiate. Acum, deoarece densitatea punctelor verzi este mare doar în regiunea verde selectată, în acea regiune punctele sunt destul de aproape de hiperplanul plauzibil, astfel încât acele hiperplane au fost alese. Aveți grijă cu parametrul gamma, deoarece acest lucru poate avea o influență foarte proastă asupra rezultatelor modelului dvs. dacă îl setați la o valoare foarte mare (ceea ce este o „valoare foarte mare” depinde de densitatea punctelor de date).,pentru acest exemplu, cele mai bune valori pentru C și Gamma sunt 1.0 și 1.0. Acum, dacă vom rula modelul nostru de pe setul de testare vom obține următoarea diagramă:

Și Matricea Confuzie pare ca acest lucru:

după Cum puteți vedea, avem doar 3 rezultate Fals Pozitive și doar 4 Fals Negative., Precizia acestui model este de 93%, ceea ce este un rezultat foarte bun, am obținut un scor mai bun decât folosind KNN (care a avut o precizie de 80%).notă: precizia nu este singura metrică utilizată în ML și, de asemenea, nu este cea mai bună metrică pentru a evalua un model, din cauza paradoxului de precizie. Folosim această metrică pentru simplitate, dar mai târziu, în capitolul metrici pentru evaluarea algoritmilor AI, vom vorbi despre paradoxul preciziei și voi arăta alte metrici foarte populare utilizate în acest domeniu.,
concluzii
În acest articol am văzut un algoritm de învățare supravegheat foarte popular și puternic, mașina Vector de suport. Am învățat ideea de bază, ce este un hyperplan, care sunt vectorii de sprijin și de ce sunt atât de importanți. Am văzut, de asemenea, o mulțime de reprezentări vizuale, care ne-au ajutat să înțelegem mai bine toate conceptele.un alt subiect important pe care l-am atins este trucul Kernel-ului, care ne-a ajutat să rezolvăm probleme neliniare.pentru a avea un model mai bun, am văzut tehnici pentru a regla algoritmul., La sfârșitul articolului am avut un exemplu de cod în Python, care ne-a arătat cum putem folosi algoritmul KNN.ca gânduri finale, aș dori să dau câteva argumente pro & contra și unele cazuri de Utilizare populare.,
Pro
- SVN poate fi foarte eficient, deoarece foloseste doar un subset de date de instruire, numai suport vectori
- Funcționează foarte bine pe seturi de date mai mici, non-linear de seturi de date și de înaltă spații dimensionale
- Este foarte eficient în cazurile în care numărul de dimensiuni este mai mare decât numărul de probe
- poate fi de mare precizie, uneori se poate efectua chiar mai bine decât rețelele neuronale
- Nu foarte sensibil la overfitting
Dezavantaje
- timpul de Instruire este mare atunci când avem seturi mari de date
- atunci Când setul de date are mai mult zgomot (am.,e. țintă sunt clase care se suprapun) SVM nu face bine
Popular Cazuri de Utilizare
- Text Clasificare
- Detectarea spam
- analiza Sentiment
- Aspect pe bază de recunoaștere
- Aspect pe bază de recunoaștere
- cifre scrise de Mână de recunoaștere