
Po vytvoření model strojového učení, dalším krokem je vyhodnotit model výkon a pochopit, jak dobrý náš model je proti referenční model., Hodnocení metrických být použita, závisí na typu problému, který se snažíte řešit —ať už je to pod dozorem nebo bez dozoru problém, a pokud se jedná o klasifikaci nebo regresi.
v tomto příspěvku budu hovořit o dvou důležitých metrikách hodnocení používaných pro regresní problémy a zvýraznit klíčový rozdíl mezi nimi.
r-na druhou, také známý jako stanovení koeficientu, definuje stupeň, do kterého lze rozptyl v závislé proměnné (nebo cíli) vysvětlit nezávislou proměnnou (rysy).,
pojďme to pochopit příkladem-řekněme, že hodnota R-na druhou pro konkrétní model vyjde na 0,7. To znamená, že 70% změny závislé proměnné je vysvětleno nezávislými proměnnými.
v Ideálním případě bychom chtěli, aby nezávislé proměnné jsou schopni vysvětlit všechny rozdíly v cílové proměnné. V tomto scénáři by hodnota R na druhou byla 1. Můžeme tedy říci, že vyšší hodnota R-na druhou, lepší v modelu.,
takže jednoduše řečeno, čím vyšší je R na druhou, tím více variací je vysvětleno vašimi vstupními proměnnými, a proto je lepší váš model. Také r-na druhou by se pohyboval od 0 do 1. Zde je vzorec pro výpočet R-na druhou-
R na druhou se vypočítá vydělením součtu čtverců reziduí z regresní model (dané SSres) celkový součet čtverců chyb od průměru model (dané SStot) a pak to odečíst od 1.,
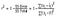
Jednu nevýhodu r-druhou je, že to předpokládá, že všechny proměnné pomáhá vysvětlovat rozdíly v cíli, který nemusí být vždy pravda. Pokud například k datům přidáme nové funkce (které mohou nebo nemusí být užitečné), hodnota R na druhou pro model by se buď zvýšila, nebo zůstala stejná, ale nikdy by se nesnížila.
o to se stará mírně upravená verze r-na druhou, nazývaná upravená r-na druhou.,
upravený R-na druhou
podobně jako R-na druhou, upravený r-na druhou měří změnu závislé proměnné (nebo cíle), vysvětleno pouze funkcemi, které jsou užitečné při vytváření předpovědí. Na rozdíl od R-na druhou, upravený R-na druhou by vás potrestal za přidání funkcí, které nejsou užitečné pro předpovídání cíle.
pojďme matematicky pochopit, jak je tato funkce umístěna v upraveném R-čtverci., Tady je vzorec pro upravené r-kvadrát,

R^2 je r-na druhou vypočítat, N je počet řádků a M je počet sloupců. Jak se počet funkcí zvyšuje, hodnota ve jmenovateli klesá.
- pokud se R2 zvýší o významnou hodnotu, pak se upravený r-na druhou zvýší.
- pokud nedojde k žádné významné změně R2, upravený r2 by se snížil.