
Qué es el objetivo de punto de recuperación (RPO)
El objetivo de punto de recuperación (rpo) describe un período de tiempo en el que las operaciones de una empresa deben restaurarse después de un evento perturbador, por ejemplo, un ciberataque, un desastre natural o un fallo en las comunicaciones.
es una parte importante de su plan de recuperación ante desastres y, por lo general, se combina con el objetivo de tiempo de recuperación (RTO), el tiempo máximo para restaurar funciones críticas después de un evento perturbador.,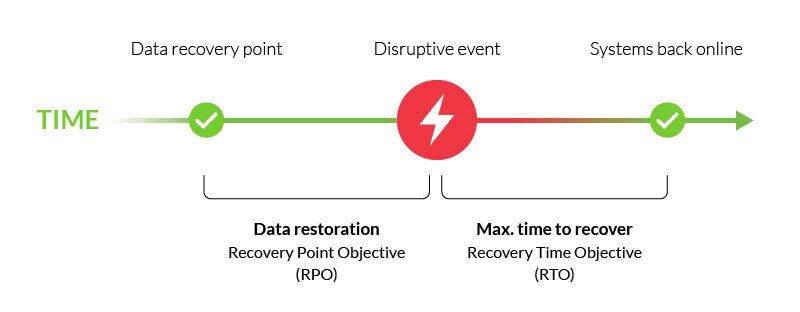
cada uno de los diferentes procesos de su empresa, incluidas las redes de comunicación y la infraestructura, debe tener RPOs únicos, dependiendo de sus funciones e importancia. Aquí cubriremos cómo los RPOs para la recuperación de datos deben definirse de acuerdo con sus necesidades de cumplimiento y objetivos comerciales.
definir sus RPOs
normalmente, los RPOs se establecen de acuerdo con la frecuencia con la que se actualizan los archivos. Esto garantiza que, tras una interrupción del servicio, las operaciones restauradas contengan la versión más actualizada de sus datos.,
por ejemplo, los archivos actualizados con frecuencia necesitan un RPO corto (no más de unos minutos). Esto significa que después de un evento disruptivo, las operaciones se pueden restaurar con una pérdida de datos mínima.
Los Factores que pueden influir en sus rpo incluyen:
- industria: las empresas que tratan con información altamente dinámica o confidencial (por ejemplo, registros de salud o transacciones financieras) actualizan sus archivos con más frecuencia que las que tratan con archivos estáticos.
- almacenamiento de Datos – ¿Cómo se almacenan los datos (por ejemplo, en dispositivos físicos, la nube, etc.,) puede afectar la rapidez con que se puede recuperar después de una interrupción del servicio.
- consideraciones de cumplimiento: numerosos esquemas de cumplimiento contienen cláusulas relacionadas con la recuperación ante desastres y la disponibilidad de datos. Por ejemplo, la certificación SOC 2 requiere un cierto nivel de disponibilidad de datos e integridad de procesamiento, lo que puede afectar la cantidad aceptable de datos que se pueden perder después de una interrupción del servicio.
Una vez definidos, los RPOs deben convertirse en las piedras angulares de su plan de continuidad de negocio, sirviendo como objetivos para los procesos que detalla.,
en su plan, se deben establecer diferentes rpo para varias unidades de negocio. Por ejemplo, un proceso de datos de misión crítica, como las transacciones financieras, necesita un RPO más corto que los archivos que se actualizan con menos frecuencia, como los registros de los empleados.
los siguientes son niveles de muestra que puede usar al configurar los RPOs requeridos para sus unidades de negocio:
0-1 hora
estas son operaciones críticas que no pueden permitirse perder más de una hora de datos., Las transacciones comerciales y de datos suelen ser de mayor volumen y más dinámicas, lo que hace que su recreación a menudo sea imposible debido al número de variables involucradas.
ejemplos de este nivel incluyen transacciones bancarias, su sistema CRM y registros de pacientes.
1-4 horas
Las unidades de negocio que pueden permitirse la pérdida de datos de hasta cuatro horas son de naturaleza semi-crítica. Los ejemplos incluyen registros de chat de clientes y servidores de archivos.
4-12 horas
Las unidades de negocio que entran en esta categoría no pueden tolerar perder más de 12 horas de información., Los ejemplos incluyen datos de marketing y ventas.
13-24 horas
Las unidades de negocio que componen esta categoría manejan datos semi-importantes, y requieren un RPO que se remonta un máximo de 24 horas. Esto puede incluir los departamentos de Recursos Humanos y compras, que actualizan los datos con menos frecuencia que los sectores salientes de un negocio.
Failover y RPO
Failover es el proceso de cambiar entre sus sistemas primario y de respaldo durante un evento disruptivo o tiempo de inactividad planificado del sistema (por ejemplo, mantenimiento de rutina).,
al elegir una solución de conmutación por error, es importante tener en cuenta los RPO de su organización para evitar perder una cantidad inaceptable de datos al cambiar a un servidor de copia de seguridad.
por ejemplo, un RPO de diez minutos significa que su solución de conmutación por error tiene que responder dentro de ese período de tiempo para garantizar que no pierda más de diez minutos de datos.
Los métodos de conmutación por error incluyen:
- servicios DNS: un servicio DNS enruta el tráfico de una solución de hardware a un centro de datos externo. Esto es útil para la recuperación de centros de datos cruzados, en el caso de que todo un centro de datos se caiga., Este proceso, sin embargo, tiene una serie de inconvenientes potenciales, incluidos los retrasos relacionados con TTL y la degradación del servicio, que podrían aumentar el tiempo de recuperación de datos.Además, el proceso de enrutamiento podría hacer que la conmutación por error sea desigual, ya que los ISP podrían continuar enrutando el tráfico al servidor incorrecto hasta que se actualice su caché DNS.
- Soluciones de Hardware-los dispositivos físicos se mantienen en el sitio. En el caso de que uno se caiga, el tráfico se redirige automáticamente a un servidor de copia de seguridad.Esta solución no tiene ninguno de los problemas de latencia asociados con la conmutación por error de DNS., Sin embargo, requiere el alojamiento de su sitio de copia de seguridad en la misma ubicación física que su servidor de origen. Esto generalmente se considera una mala práctica, ya que expone el sitio de copia de seguridad a muchas de las amenazas que afectarían a su clúster de servidores principal (por ejemplo, falla de la red eléctrica local o desastres naturales).
- Servicios en el borde: la conmutación por error es administrada fuera del sitio por un tercero, donde los datos se pueden enrutar sin problemas durante un evento disruptivo., La conmutación por error en el borde toma lo mejor de las soluciones basadas en DNS y hardware: no hay retrasos relacionados con TTL ni costos adicionales asociados con el mantenimiento de los dispositivos físicos. Esto garantiza una pérdida mínima de datos, lo que le permite mantener sus objetivos de RPO.
vea cómo Imperva Site Failover puede ayudarle con la alta disponibilidad .
cumplir sus objetivos de punto de recuperación con Imperva
Imperva ofrece un servicio de vanguardia que proporciona soluciones de seguridad, rendimiento y disponibilidad para sitios web y aplicaciones web.,
la función de conmutación por error que ofrecemos permite a nuestros clientes mover su tráfico a un sitio de copia de seguridad en cuestión de segundos, ya sea un servidor local secundario o un centro de datos ubicado en el otro lado del mundo. Esto garantiza una funcionalidad continua después de un evento disruptivo, lo que le permite configurar y mantener RPOs agresivos sin tener que preocuparse por retrasos relacionados con TTL o mantenimiento y seguridad del dispositivo.,
nuestro servicio de conmutación por error viene aumentado por otras características de alta disponibilidad, incluida una plataforma de CDN global de alta capacidad, un conjunto integral de soluciones de mitigación de DDoS y un equilibrador de carga de capa de aplicación.