ANOVA også kjent som Analysis of Variance er en kraftig statistisk metode for å teste en hypotese som involverer mer enn to grupper (også kjent som behandlinger). Imidlertid, ANOVA er begrenset i å gi en detaljert innsikt mellom ulike behandlinger eller grupper, og dette er hvor Tukey (T) test også kjent som T-test kommer i å spille. I denne opplæringen vil jeg vise hvordan å forberede input filer og kjøre ANOVA og Tukey test i R programvare., For detaljert informasjon om ANOVA og R, kan du lese denne artikkelen på denne linken.
Trinn 1.0 Laste ned og installere R programvare og R-studio
- Last ned og installer den nyeste versjonen av R-programvaren fra denne linken
- Last ned og installer R-studio fra denne linken
- til Slutt, installere biblioteket qtl i R
Trinn 1.,2 – Oppsett arbeidsmappe følgende trinnene nedenfor:
Opprette en input-fil som vist i eksemplet nedenfor:

Trinn 2: Kjør ANOVA i R
2.,1 Import R pakken
Installer R pakken agricolae og åpne biblioteket for å skrive under kommando linje:
library(agricolae)
Merk: Husk å installere riktig R-pakken for ANOVA!
2.2 Import av data
Importere dine data ved å skrive under kommando linje:
data= read.table(file = "fileName.txt", header = T)2.3 Kontrollere data
Når dataene er importert, sjekk det ved å skrive under kommando linje:
head(data_pressure)tail(data_pressure)2.,4 Oppførsel ANOVA
Nå, Bare kjør ANOVA ved å skrive under kommando linjer:
data.lm <- lm(data$Dependent_variable ~ data$Treatment, data = data)data.av <- aov(data.lm)summary(data.av)resultatene skal se ut som vist nedenfor:
Fra sammendraget utgang, man kan tolke at det er en signifikant forskjell (dvs. P < 0.001) mellom Treatments, men vi perfom Tukey ‘ s Test for å undersøke forskjeller mellom alle treaments ved hjelp av fremgangsmåten nedenfor.
3.,0 Gjennomføre Tukey test
Skriv inn kommandoene nedenfor for å kjøre Tukey test:
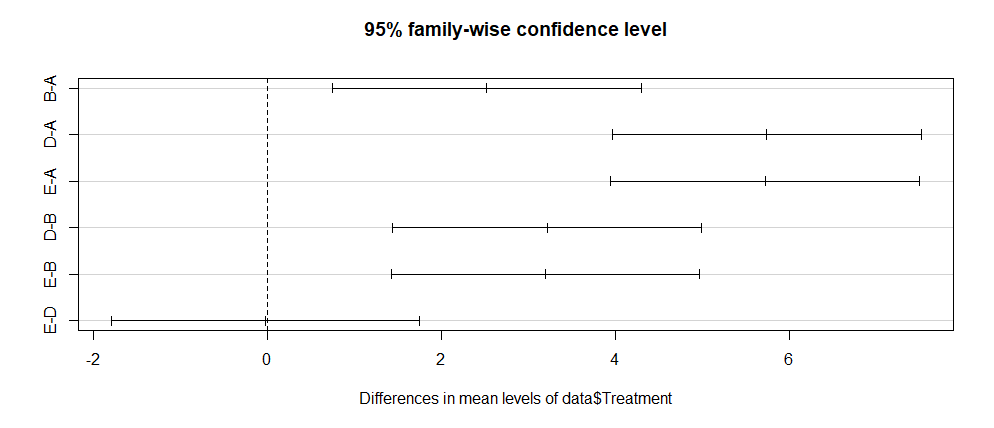
data.test <- TukeyHSD(data.av)data.testNedenfor er et sammendrag av Tukey test:
Fra over T-test, kan man konkludere med at det er en betydelig forskjell i de fleste grupper, bortsett fra mellom-gruppene E-D i P <0.,001
Finally, one can plot the above results using the below command:
plot(data.test)Output: