
Hva er gjenoppretting punkt mål (RPO)
Gjenoppretting punkt mål (RPO) beskriver en periode hvor en virksomhet er drift skal være tilbake etter en diskontinuerlig hendelse, for eksempel, en cyberattack, naturkatastrofer eller kommunikasjon svikt.
Det er en viktig del av din disaster recovery plan, og er vanligvis koblet sammen med restitusjonstid mål (RTO)—maksimal tid å gjenopprette kritiske funksjoner etter en diskontinuerlig hendelse.,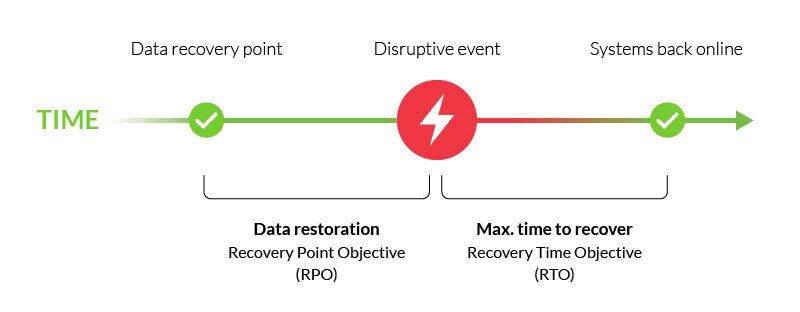
Hver av bedriftens ulike prosesser, inkludert kommunikasjon, nettverk og infrastruktur bør ha unike RPOs, avhengig av deres funksjoner og betydning. Her vil vi dekke hvordan RPOs for gjenoppretting av data, bør være definert i henhold til dine krav og forretningsmål.
Definere din RPOs
Vanligvis, RPOs er angitt i henhold til frekvens med hvilke filer som er oppdatert. Dette sikrer at etter en tjeneste avbrudd, din restaurert operasjoner inneholder den mest oppdaterte versjonen av dine data.,
For eksempel, ofte oppdatert filer trenger en kort (ikke lenger enn et par minutter) RPO. Dette betyr at å følge en diskontinuerlig hendelse, operasjoner kan gjenopprettes med minimalt tap av data.
Faktorene som kan påvirke din RPOs inkluderer:
- Industri – Bedrifter arbeider med svært dynamisk eller sensitiv informasjon (f.eks., helse-poster eller finansielle transaksjoner) oppdatering av deres filer oftere enn de som arbeider med statiske filer.
- datalagring – for Hvordan dataene er lagret (for eksempel, i fysisk apparater, sky, etc.,) kan påvirke hvor raskt det kan hentes etter en driftsforstyrrelse.
- Samsvar hensyn – Mange samsvar ordninger inneholde klausuler som arbeider med katastrofe gjenoppretting og data tilgjengelighet. For eksempel, SOC 2 sertifisering krever et visst nivå av data tilgjengelighet og behandling integritet, noe som kan påvirke akseptabel mengde data som kan gå tapt etter en driftsforstyrrelse.
Når den er definert, RPOs bør bli bærebjelkene i virksomheten kontinuitet plan, tjene som mål for de prosesser det detaljer.,
I planen, ulike RPOs bør settes for ulike forretningsenheter. For eksempel, en oppgave kritiske data prosess, for eksempel finansielle transaksjoner, trenger en kortere RPO enn mindre vanlige oppdaterte filer, for eksempel ansatte.
Følgende er eksempel tiers du kan bruke når du angir de nødvendige RPOs for din bedrift enheter:
0-1 time
Disse er kritiske operasjoner som ikke har råd til å miste mer enn en time er verdt av data., Business data og transaksjoner er vanligvis høyere i volum og mer dynamisk, noe som gjør deres rekreasjon ofte umulig på grunn av antallet variabler involvert.
Eksempler på dette nivået inkluderer banktransaksjoner, ditt CRM-system, og pasienten poster.
1-4 timer
forretningsenheter som har råd til data, tap av opp til fire timer er semi-kritiske i naturen. Eksempler inkluderer kunde chat logger og filservere.
4-12 timer
forretningsenheter som faller innenfor denne kategorien kan ikke tolerere å miste mer enn 12 timer igjen av informasjon., Eksempler omfatter markedsføring og salg av data.
13-24 timer
forretnings-enheter som utgjør denne kategorien håndtere semi-viktige data, og krever en RPO som går tilbake maksimalt 24 timer. Dette kan inkludere de menneskelige ressursene og kjøpe avdelinger, som oppdaterer data sjeldnere enn utgående deler av en virksomhet.
– Failover og RPO
Failover er prosessen med å bytte mellom primær-og backup-systemer i løpet av en diskontinuerlig hendelse eller planlagt system nedetid (f.eks., rutinemessig vedlikehold).,
Når du velger en failover-løsning, er det viktig å vurdere organisasjonens RPOs for å unngå å miste en uakseptabel mengden av data når du bytter til en backup-server.
For eksempel, en ti-minutters RPO betyr at failover-løsning har til å svare innen den tidsramme for å sikre at du taper ikke mer enn ti minutter av data.
Failover-metoder omfatter:
- DNS-tjenester – EN DNS-tjeneste ruter trafikk fra en hardware-løsning til en off-site data center. Dette er nyttig for kryss-data-recovery center, i tilfelle at en hel data center går ned., Denne prosessen, imidlertid, har en rekke potensielle ulempene, inkludert TTL knyttet til forsinkelser og service-degradering, som kan øke data utvinning tid.I tillegg, ruting prosessen kunne gjøre failover ujevn, som Isper kan fortsette ruting av trafikk til feil server til sine DNS-cache er oppdatert.
- Maskinvare-løsninger – Fysiske produkter er holdt på området. I tilfelle at en går ned, trafikk er automatisk omdirigert til en backup-server.Denne løsningen har ingen av latency problemer forbundet med DNS-failover., Men, det krever hosting av din backup-området i den samme fysiske sted som den opprinnelige serveren. Dette er generelt ansett som en dårlig praksis, som det utsetter backup nettstedet til mange av de truslene som vil påvirke din viktigste server cluster (f.eks., lokale kraftnettet feil eller naturkatastrofer).
- På-kanten – tjenester- Failover er klart off-site av en tredjepart, der data kan være sømløst rutet under en diskontinuerlig hendelse., På kanten failover tar det beste fra begge DNS-og maskinvare-baserte løsninger—det er ingen TTL knyttet til forsinkelser eller ekstra kostnader forbundet med å opprettholde fysisk apparater. Dette sikrer minimal tap av data, slik at du kan opprettholde din RPO mål.
Se hvordan Imperva Nettstedet Failover kan hjelpe deg med høy tilgjengelighet .
Møte dine recovery point objektive mål med Imperva
Imperva tilbyr en på-kanten-tjeneste som gir sikkerhet, ytelse og tilgjengelighet øke løsninger for nettsteder og web-applikasjoner.,
failover-funksjonen tilbyr vi gjør våre kunder til å flytte trafikk til en backup nettsted i løpet av sekunder, det være seg en videregående på lokal server eller et datasenter som er plassert på den andre siden av verden. Dette sikrer fortsatt funksjonalitet etter en diskontinuerlig hendelse, slik at du kan sette og opprettholde aggressiv RPOs uten å bekymre deg for TTL knyttet til forsinkelser eller utstyr vedlikehold og sikkerhet.,
Vår failover-tjenesten kommer forsterket av andre funksjoner for høy tilgjengelighet, som inkluderer en high-capacity-kort global CDN-plattformen, omfattende pakke av DDoS avbøtende løsninger og et program-lag load balancer.