
Wat is recovery point objective (RPO)
Recovery point objective (RPO) beschrijft een periode waarin de activiteiten van een onderneming moeten worden hersteld na een verstorende gebeurtenis, bijvoorbeeld een cyberaanval, natuurramp of communicatiestoring.
het is een belangrijk onderdeel van uw disaster recovery plan, en wordt meestal gekoppeld aan recovery time objective (RTO)—de maximale tijd om kritieke functies te herstellen na een verstorende gebeurtenis.,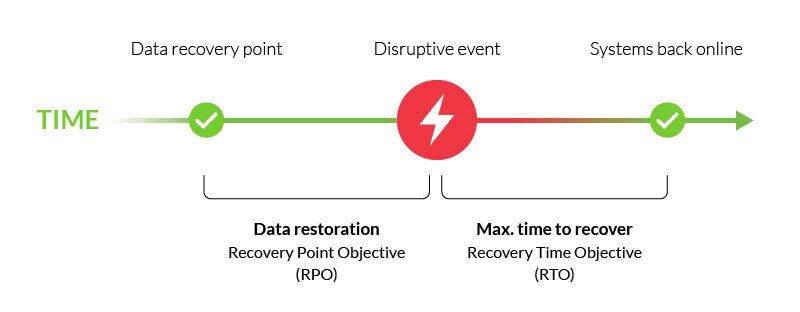
elk van de verschillende processen van uw onderneming, inclusief communicatienetwerken en infrastructuur, moet unieke RPO ‘ s hebben, afhankelijk van hun functies en belang. Hier zullen we behandelen hoe RPO ‘ s voor data recovery moeten worden gedefinieerd op basis van uw compliance behoeften en zakelijke doelen.
uw RPO ’s definiëren
normaal gesproken worden RPO’ s ingesteld op basis van de frequentie waarmee bestanden worden bijgewerkt. Dit zorgt ervoor dat na een serviceonderbreking uw herstelde bewerkingen de meest up-to-date versie van uw gegevens bevatten.,
bijvoorbeeld, vaak bijgewerkte bestanden hebben een korte (niet langer dan een paar minuten) RPO nodig. Dit betekent dat na een verstorende gebeurtenis, operaties kunnen worden hersteld met minimaal verlies van gegevens.
factoren die uw RPO ‘ s kunnen beïnvloeden zijn onder meer:
- industrie – ondernemingen die omgaan met zeer dynamische of gevoelige informatie (bijvoorbeeld gezondheidsdossiers of financiële transacties) werken hun bestanden vaker bij dan die met statische bestanden.
- data storage-hoe uw gegevens worden opgeslagen (bijvoorbeeld in fysieke apparaten, de cloud, enz.,) kan invloed hebben op hoe snel het kan worden opgehaald na een onderbreking van de dienst.
- Nalevingsoverwegingen-tal van nalevingsregelingen bevatten clausules over noodherstel en beschikbaarheid van gegevens. SOC 2-certificering vereist bijvoorbeeld een bepaalde mate van beschikbaarheid van gegevens en verwerkingsintegriteit, wat van invloed kan zijn op de aanvaardbare hoeveelheid gegevens die verloren kunnen gaan na een onderbreking van de dienstverlening.
eenmaal gedefinieerd, moeten RPO ‘ s de hoekstenen worden van uw bedrijfscontinuïteitsplan en dienen als doelen voor de processen die it-gegevens bevatten.,
in uw plan moeten verschillende RPO ‘ s worden ingesteld voor verschillende business units. Een bedrijfskritisch gegevensproces, zoals financiële transacties, heeft bijvoorbeeld een kortere RPO nodig dan minder vaak bijgewerkte bestanden, zoals personeelsrecords.
volgende zijn voorbeeldlagen die u kunt gebruiken bij het instellen van de vereiste RPO ‘ s voor uw business units:
0-1 hour
Dit zijn kritieke bewerkingen die het zich niet kunnen veroorloven om meer dan een uur aan gegevens te verliezen., Zakelijke en datatransacties zijn meestal groter in volume en dynamischer, waardoor hun recreatie vaak onmogelijk is vanwege het aantal betrokken variabelen.
voorbeelden van dit niveau zijn banktransacties, uw CRM-systeem en patiëntendossiers.
1-4 uur
bedrijfseenheden die gegevensverlies tot vier uur kunnen veroorloven, zijn semi-kritisch van aard. Voorbeelden zijn chatlogs van klanten en bestandsservers.
4-12 uur
bedrijfseenheden die binnen deze categorie vallen, kunnen het verlies van meer dan 12 uur aan informatie niet verdragen., Voorbeelden hiervan zijn marketing-en verkoopgegevens.
13-24 uur
de business units die deze categorie omvatten, verwerken semi-belangrijke gegevens en vereisen een RPO die maximaal 24 uur teruggaat. Dit kan onder meer de human resources en inkoop afdelingen, die gegevens minder vaak dan uitgaande sectoren van een bedrijf bij te werken.
Failover en RPO
Failover is het proces van het schakelen tussen uw primaire en back-upsystemen tijdens een verstorende gebeurtenis of geplande uitvaltijd van het systeem (bijvoorbeeld routinematig onderhoud).,
bij het kiezen van een failover-oplossing is het belangrijk om rekening te houden met de RPO ‘ s van uw organisatie om te voorkomen dat een onaanvaardbare hoeveelheid gegevens verloren gaat bij het overschakelen naar een back-upserver.
een RPO van tien minuten betekent bijvoorbeeld dat uw failover-oplossing binnen die tijd moet reageren om ervoor te zorgen dat u niet meer dan tien minuten aan gegevens verliest.
Failover-methoden omvatten:
- DNS – services-Een DNS-service stuurt verkeer van een hardwareoplossing naar een extern datacenter. Dit is handig voor cross-data center herstel, in het geval dat een volledig datacenter naar beneden gaat., Dit proces, echter, heeft een aantal potentiële nadelen, met inbegrip van TTL gerelateerde vertragingen en degradatie van de dienst, die de tijd van de gegevensterugwinning kunnen verhogen.Bovendien kan het routeringsproces failover ongelijkmatig maken, omdat ISP ‘ s verkeer naar de verkeerde server kunnen blijven routeren totdat hun DNS-cache is bijgewerkt.
- hardwareoplossingen-fysieke apparaten worden ter plaatse bewaard. In het geval dat een down gaat, verkeer wordt automatisch omgeleid naar een back-up server.Deze oplossing heeft geen van de latency problemen geassocieerd met DNS failover., Echter, het vereist de hosting van uw back-up site op dezelfde fysieke locatie als uw origin server. Dit wordt over het algemeen als een slechte praktijk beschouwd, omdat het de back-up site blootstelt aan veel van de bedreigingen die uw hoofdservercluster zouden beïnvloeden (bijvoorbeeld, lokale stroomnetstoring of natuurrampen).
- On-edge services-Failover wordt off-site beheerd door een derde partij, waar gegevens naadloos kunnen worden gerouteerd tijdens een verstorende gebeurtenis., On-edge failover neemt het beste van zowel DNS als hardware-gebaseerde oplossingen—er zijn geen TTL-gerelateerde vertragingen of extra kosten in verband met het onderhoud van fysieke apparaten. Dit zorgt voor minimaal verlies van gegevens, zodat u uw RPO doelen te behouden.
bekijk hoe Imperva Site Failover u kan helpen met hoge beschikbaarheid .
voldoen aan uw doelstelling voor herstelpunten met Imperva
Imperva biedt een on-edge service die beveiligings -, prestatie-en beschikbaarheidsverbeterende oplossingen biedt voor websites en webapplicaties.,
de failover-functie die wij aanbieden stelt onze klanten in staat om hun verkeer binnen enkele seconden naar een back-upsite te verplaatsen, of het nu een secundaire server op locatie is of een datacenter aan de andere kant van de wereld. Dit zorgt voor voortdurende functionaliteit na een verstorende gebeurtenis, zodat u agressieve RPO ‘ s kunt instellen en onderhouden zonder zich zorgen te hoeven maken over TTL-gerelateerde vertragingen of onderhoud en beveiliging van apparaten.,
onze failover-service wordt aangevuld met andere functies met hoge beschikbaarheid, waaronder een wereldwijd CDN-platform met hoge capaciteit, een uitgebreid pakket DDoS-mitigatieoplossingen en een load balancer met applicatielagen.