
vad är recovery point objective (RPO)
Recovery point objective (RPO) beskriver en tidsperiod under vilken ett företags verksamhet måste återställas efter en störande händelse, t.ex. ett cyberattack, naturkatastrof eller Kommunikationsfel.
det är en viktig del av din katastrofåterställningsplan och är vanligtvis parat med recovery time objective (RTO)—den maximala tiden för att återställa kritiska funktioner efter en störande händelse.,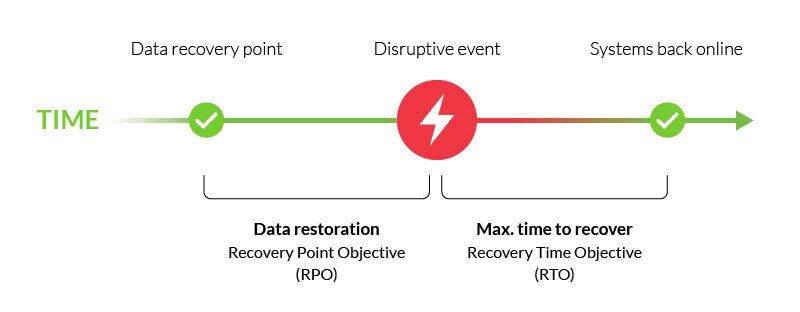
var och en av företagets olika processer, inklusive kommunikationsnät och infrastruktur bör ha unika RPOs, beroende på deras funktioner och betydelse. Här kommer vi att täcka hur RPOs för dataåterställning ska definieras enligt dina efterlevnadsbehov och affärsmål.
definiera din RPOs
typiskt, RPOs ställs in beroende på frekvensen med vilken filer uppdateras. Detta säkerställer att efter ett serviceavbrott innehåller dina återställda operationer den mest aktuella versionen av dina data.,
till exempel behöver ofta uppdaterade filer en kort (inte längre än några minuter) RPO. Detta innebär att efter en störande händelse, verksamheten kan återställas med minimal dataförlust.
faktorer som kan påverka dina RPOs inkluderar:
- industriföretag som arbetar med mycket dynamisk eller känslig information (t.ex. hälsojournaler eller finansiella transaktioner) uppdaterar sina filer oftare än de som hanterar statiska filer.
- datalagring – hur dina data lagras (t.ex. i fysiska apparater, molnet etc.,) kan påverka hur snabbt det kan hämtas efter en serviceavbrott.
- Compliance considerations – talrika compliance schemes innehåller klausuler om katastrofåterställning och datatillgänglighet. Till exempel kräver SOC 2-certifiering en viss nivå av datatillgänglighet och bearbetningsintegritet, vilket kan påverka den acceptabla mängd data som kan gå förlorad efter en tjänstestörning.
en gång definierad, bör RPOs bli hörnstenarna i din kontinuitetsplan, som tjänar som mål för de processer som den beskriver.,
i din plan bör olika RPOs ställas in för olika affärsenheter. Till exempel behöver en affärskritisk dataprocess, till exempel finansiella transaktioner, en kortare RPO än mindre ofta uppdaterade filer, till exempel personalposter.
Följande är provnivåer som du kan använda när du ställer in nödvändiga RPOs för dina affärsenheter:
0-1 timme
det här är kritiska operationer som inte har råd att förlora mer än en timmes värde av data., Affärstransaktioner och datatransaktioner är vanligtvis högre i volym och mer dynamiska, vilket gör deras rekreation ofta omöjlig på grund av antalet inblandade variabler.
exempel på denna nivå inkluderar banktransaktioner, ditt CRM-system och patientposter.
1-4 timmar
affärsenheter som har råd med dataförlust på upp till fyra timmar är halvkritiska i naturen. Exempel inkluderar kundchattloggar och filservrar.
4-12 timmar
affärsenheter som faller inom denna kategori kan inte tolerera att förlora mer än 12 timmar av information., Exempel är marknadsföring och försäljningsdata.
13-24 timmar
de affärsenheter som omfattar denna kategori hanterar semi-viktiga data och kräver en RPO som går tillbaka högst 24 timmar. Detta kan omfatta personalresurser och inköpsavdelningar, som uppdaterar data mindre ofta än utgående sektorer i ett företag.
Failover och RPO
Failover är processen att växla mellan dina primära och säkerhetskopieringssystem under en störande händelse eller planerad systemstopp (t.ex. rutinunderhåll).,
När du väljer en failoverlösning är det viktigt att tänka på organisationens RPOs för att undvika att förlora en oacceptabel mängd data när du byter till en backup-server.
till exempel innebär en tio minuters RPO att din failoverlösning måste svara inom den tidsramen för att säkerställa att du inte förlorar mer än tio minuters data.
Failovermetoder inkluderar:
- DNS – tjänster-en DNS-tjänst rutter trafik från en hårdvarulösning till en off-site datacenter. Detta är användbart för cross-data center recovery, om ett helt datacenter går ner., Denna process har dock ett antal potentiella nackdelar, inklusive TTL-relaterade förseningar och serviceförstöring, vilket kan öka tiden för dataåterställning.Dessutom kan routingprocessen göra failover ojämn, eftersom ISPs kan fortsätta att dirigera trafik till fel server tills deras DNS-cache uppdateras.
- hårdvarulösningar – fysiska apparater hålls på plats. I händelse av att man går ner, omdirigeras trafiken automatiskt till en backup-server.Denna lösning har ingen av de latensproblem som är associerade med DNS failover., Det kräver dock värd för din backup webbplats på samma fysiska plats som ursprungsservern. Detta anses i allmänhet vara en dålig praxis, eftersom det exponerar säkerhetskopieringswebbplatsen för många av de hot som skulle påverka din huvudserverkluster (t.ex. lokalt strömavbrott eller naturkatastrofer).
- on-edge – tjänster-Failover hanteras utanför webbplatsen av en tredje part, där data kan smidigt dirigeras under en störande händelse., On-edge failover tar det bästa av både DNS och hårdvarubaserade lösningar – det finns inga TTL-relaterade förseningar eller extra kostnader i samband med underhåll av fysiska apparater. Detta säkerställer minimal dataförlust, så att du kan behålla dina RPO-mål.
se hur Imperva webbplats Failover kan hjälpa dig med hög tillgänglighet .
uppfylla dina målmål för återställningspunkten med Imperva
Imperva erbjuder en tjänst på kanten som ger säkerhet, prestanda och tillgänglighet förbättra lösningar för webbplatser och webbapplikationer.,
funktionen failover som vi erbjuder gör det möjligt för våra kunder att flytta sin trafik till en reservplats inom några sekunder, vare sig det är en sekundär lokal server eller ett datacenter placerat på andra sidan världen. Detta säkerställer fortsatt funktionalitet efter en störande händelse, så att du kan ställa in och behålla aggressiva RPOs utan att behöva oroa sig för TTL relaterade förseningar eller underhåll och säkerhet.,
vår failover-tjänst förstärks av andra funktioner med hög tillgänglighet, inklusive en global CDN-plattform med hög kapacitet, en omfattande svit av DDoS-begränsningslösningar och en applikationslastbalansare.