
Was ist Wiederherstellungspunktziel (RPO)
Wiederherstellungspunktziel (RPO) beschreibt einen Zeitraum, in dem der Betrieb eines Unternehmens nach einem störenden Ereignis wiederhergestellt werden muss, z. B. einem Cyberangriff, einer Naturkatastrophe oder einem Kommunikationsausfall.
Es ist ein wichtiger Teil Ihres Disaster-Recovery-Plan, und ist in der Regel mit Recovery Time Objective (RTO) gepaart—die maximale Zeit, um kritische Funktionen nach einem störenden Ereignis wiederherzustellen.,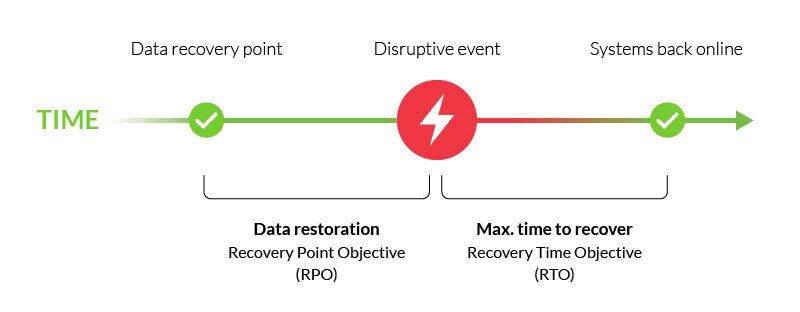
Jeder der verschiedenen Prozesse Ihres Unternehmens, einschließlich Kommunikationsnetzwerke und-infrastrukturen, sollte je nach Funktion und Bedeutung eindeutige RPOs haben. Hier behandeln wir, wie RPOs für die Datenwiederherstellung entsprechend Ihren Compliance-Anforderungen und Geschäftszielen definiert werden sollten.
Definieren Ihres RPOs
Normalerweise werden RPOs entsprechend der Häufigkeit festgelegt, mit der Dateien aktualisiert werden. Dadurch wird sichergestellt, dass Ihre wiederhergestellten Vorgänge nach einer Dienstunterbrechung die aktuellste Version Ihrer Daten enthalten.,
Häufig aktualisierte Dateien benötigen beispielsweise einen kurzen (nicht länger als einige Minuten) RPO. Dies bedeutet, dass nach einem störenden Ereignis Vorgänge mit minimalem Datenverlust wiederhergestellt werden können.
Zu den Faktoren, die Ihre RPOs beeinflussen können, gehören:
- Industrieunternehmen, die mit hochdynamischen oder sensiblen Informationen (z. B. Gesundheitsakten oder Finanztransaktionen) zu tun haben, aktualisieren ihre Dateien häufiger als solche, die sich mit statischen Dateien befassen.
- Datenspeicherung-Wie Ihre Daten gespeichert werden (z. B. in physischen Appliances,in der Cloud usw.,) kann Auswirkungen darauf haben, wie schnell es nach einer Dienstunterbrechung abgerufen werden kann.
- Compliance-Überlegungen-Zahlreiche Compliance-Regelungen enthalten Klauseln zur Disaster Recovery und Datenverfügbarkeit. Beispielsweise erfordert die SOC 2-Zertifizierung ein gewisses Maß an Datenverfügbarkeit und Verarbeitungsintegrität, was sich auf die akzeptable Datenmenge auswirken kann, die nach einer Serviceunterbrechung verloren gehen kann.
Einmal definiert, sollte RPOs die Eckpfeiler Ihres Business Continuity Plans werden und als Ziele für die Prozesse dienen, die es beschreibt.,
In Ihrem Plan sollten verschiedene RPOs für verschiedene Geschäftsbereiche festgelegt werden. Beispielsweise benötigt ein geschäftskritischer Datenprozess, z. B. Finanztransaktionen, einen kürzeren RPO als weniger häufig aktualisierte Dateien, z. B. Mitarbeiterdatensätze.
Im Folgenden finden Sie Beispielebenen, die Sie verwenden können, wenn Sie die erforderlichen RPOs für Ihre Geschäftseinheiten festlegen:
0-1 Stunde
Dies sind kritische Vorgänge, die es sich nicht leisten können, Daten im Wert von mehr als einer Stunde zu verlieren., Geschäfts-und Datentransaktionen sind in der Regel voluminöser und dynamischer, was ihre Erholung aufgrund der Anzahl der beteiligten Variablen oft unmöglich macht.
Beispiele für diese Stufe sind Bankgeschäfte, Ihr CRM-System und Patientenakten.
1-4 Stunden
Geschäftseinheiten, die Datenverlust von bis zu vier Stunden leisten können, sind halbkritischer Natur. Beispiele sind Kunden-Chat-Protokolle und Dateiserver.
4-12 Stunden
Geschäftseinheiten, die in diese Kategorie fallen, können es nicht tolerieren, Informationen im Wert von mehr als 12 Stunden zu verlieren., Beispiele sind Marketing-und Verkaufsdaten.
13-24 Stunden
Die Geschäftseinheiten, aus denen diese Kategorie besteht, verarbeiten semi-wichtige Daten und benötigen einen RPO, der maximal 24 Stunden zurückreicht. Dies kann die Personal-und Einkaufsabteilungen umfassen, die Daten seltener aktualisieren als ausgehende Sektoren eines Unternehmens.
Failover und RPO
Failover ist der Prozess des Umschaltens zwischen Ihrem primären und Backup-Systemen während eines störenden Ereignisses oder geplanter Systemausfallzeiten (z. B. routinemäßige Wartung).,
Bei der Auswahl einer Failover-Lösung ist es wichtig, die RPOs Ihrer Organisation zu berücksichtigen, um zu vermeiden, dass beim Wechsel zu einem Sicherungsserver eine inakzeptable Datenmenge verloren geht.
Ein zehnminütiger RPO bedeutet beispielsweise, dass Ihre Failover-Lösung innerhalb dieses Zeitrahmens reagieren muss, um sicherzustellen, dass Sie nicht mehr als zehn Minuten Daten verlieren.
Failover-Methoden umfassen:
- DNS-Dienste-Ein DNS-Dienst leitet den Datenverkehr von einer Hardwarelösung an ein Off-Site-Rechenzentrum weiter. Dies ist nützlich für die Cross-Data Center-Wiederherstellung, falls ein ganzes Rechenzentrum ausfällt., Dieser Prozess hat jedoch eine Reihe potenzieller Nachteile, einschließlich TTL-bedingter Verzögerungen und Service-Degradation, die die Datenwiederherstellungszeit erhöhen könnten.Darüber hinaus kann der Routingprozess das Failover ungleichmäßig gestalten, da ISPs den Datenverkehr möglicherweise weiter an den falschen Server weiterleiten, bis der DNS-Cache aktualisiert ist.
- Hardwarelösungen-Physische Appliances werden vor Ort aufbewahrt. Falls einer ausfällt, wird der Datenverkehr automatisch auf einen Sicherungsserver umgeleitet.Diese Lösung weist keine Latenzprobleme auf, die mit einem DNS-Failover verbunden sind., Es erfordert jedoch das Hosting Ihrer Backup-Site am selben physischen Speicherort wie Ihr Ursprungsserver. Dies wird im Allgemeinen als schlechte Praxis angesehen, da die Backup-Site vielen Bedrohungen ausgesetzt ist, die sich auf Ihren Hauptserver-Cluster auswirken würden (z. B. lokaler Stromnetzausfall oder Naturkatastrophen).
- On-Edge-Dienste-Failover wird von einem Dritten außerhalb des Standorts verwaltet, wobei Daten während eines störenden Ereignisses nahtlos weitergeleitet werden können., Das On-Edge-Failover nutzt das Beste aus DNS-und hardwarebasierten Lösungen—es gibt keine TTL-bedingten Verzögerungen oder zusätzlichen Kosten, die mit der Wartung physischer Appliances verbunden sind. Dies gewährleistet einen minimalen Datenverlust, sodass Sie Ihre RPO-Ziele beibehalten können.
Sehen Sie, wie Imperva Site Failover Ihnen bei hoher Verfügbarkeit helfen kann .
Mit Imperva erreichen Sie Ihre Ziele für den Wiederherstellungspunkt
Imperva bietet einen On-Edge-Service, der Sicherheits -, leistungs-und verfügbarkeitsverbessernde Lösungen für Websites und Webanwendungen bietet.,
Die von uns angebotene Failover-Funktion ermöglicht es unseren Kunden, ihren Datenverkehr innerhalb von Sekunden auf eine Backup-Site zu verschieben, sei es ein sekundärer lokaler Server oder ein Rechenzentrum auf der anderen Seite der Welt. Dies gewährleistet die fortgesetzte Funktionalität nach einem störenden Ereignis, sodass Sie aggressive RPOs einstellen und warten können, ohne sich um TTL-bedingte Verzögerungen oder Wartung und Sicherheit der Appliance kümmern zu müssen.,
Unser Failover-Service wird durch weitere Hochverfügbarkeitsfunktionen ergänzt, darunter eine globale CDN-Plattform mit hoher Kapazität, eine umfassende Suite von DDoS-Minderungslösungen und einen Load Balancer auf Anwendungsebene.