
Hvad er recovery point objective (RPO)
Recovery point objective (RPO) beskriver en periode, hvor en virksomheds operationer skal genoprettes efter en forstyrrende begivenhed, f.eks.
det er en vigtig del af din katastrofegendannelsesplan og er typisk parret med recovery time objective (RTO)—den maksimale tid til at gendanne kritiske funktioner efter en forstyrrende begivenhed.,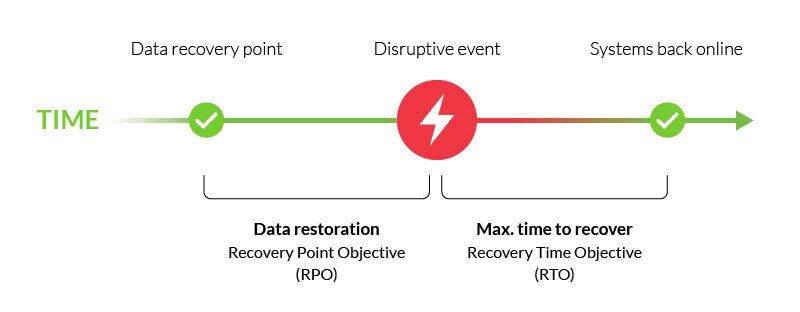
hver af din virksomheds forskellige processer, herunder kommunikationsnetværk og infrastruktur, skal have unikke RPO ‘ er afhængigt af deres funktioner og betydning. Her dækker vi, hvordan RPO ‘ er til Data recovery skal defineres i henhold til dine overholdelsesbehov og forretningsmæssige mål.
definition af dine RPO ‘er
typisk indstilles RPO’ er i henhold til den frekvens, som filer opdateres med. Dette sikrer, at dine gendannede operationer efter en serviceafbrydelse indeholder den mest opdaterede version af dine data.,for eksempel har ofte opdaterede filer brug for en kort (ikke længere end et par minutter) RPO. Det betyder, at efter en forstyrrende begivenhed, operationer kan gendannes med minimal tab af data.
faktorer, der kan påvirke dine RPO ‘ er, inkluderer:
- industri – virksomheder, der beskæftiger sig med meget dynamisk eller følsom information (f.eks. patientjournaler eller finansielle transaktioner) opdaterer deres filer oftere end dem, der beskæftiger sig med statiske filer.
- datalagring – hvordan dine data gemmes (f.eks. i fysiske apparater, skyen osv.,) kan påvirke, hvor hurtigt det kan hentes efter en serviceafbrydelse.
- Overholdelsesovervejelser-adskillige overholdelsesordninger indeholder klausuler, der beskæftiger sig med gendannelse af katastrofer og datatilgængelighed. For eksempel kræver SOC 2-certificering et vist niveau af datatilgængelighed og behandlingsintegritet, hvilket kan påvirke den acceptable mængde data, der kan gå tabt efter en serviceforstyrrelse.
når det er defineret, skal RPO ‘ er blive hjørnestenene i din forretningskontinuitetsplan, der tjener som mål for de processer, den beskriver.,
i din plan skal der indstilles forskellige RPO ‘ er for forskellige forretningsenheder. For eksempel har en missionskritisk Dataproces, såsom finansielle transaktioner, brug for en kortere RPO end mindre hyppigt opdaterede filer, såsom medarbejderregistre.
Følgende er eksempler niveauer, du kan bruge, når du vil angive de nødvendige Forskningsorganisationer for din virksomhed-enheder:
0-1 time
Disse er kritiske operationer, der ikke har råd til at miste mere end en time værd af data., Forretnings-og datatransaktioner er normalt højere i volumen og mere dynamiske, hvilket gør deres rekreation ofte umulig på grund af antallet af involverede variabler.
eksempler på dette niveau inkluderer banktransaktioner, dit CRM-system og patientjournaler.
1-4 timer
forretningsenheder, der har råd til datatab på op til fire timer, er semi-kritiske. Som eksempler kan nævnes kunde chat logs og filservere.
4-12 timer
forretningsenheder, der falder inden for denne kategori, kan ikke tolerere at miste mere end 12 timers information., Eksempler inkluderer marketing og salgsdata.
13-24 timer
de forretningsenheder, der udgør denne kategori, håndterer semi-vigtige data og kræver en RPO, der maksimalt går tilbage 24 timer. Dette kan omfatte menneskelige ressourcer og købsafdelinger, der opdaterer data sjældnere end udgående sektorer i en virksomhed.
Failover og RPO
Failover er processen med at skifte mellem dine primære og backup-systemer under en forstyrrende begivenhed eller planlagt nedetid (f.eks. rutinemæssig vedligeholdelse).,
Når du vælger en failover-løsning, er det vigtigt at overveje, om din organisation er Forskningsorganisationer for at undgå at miste en uacceptabel mængde af data, når du skifter til en backup-server.for eksempel betyder en ti minutters RPO, at din failover-løsning skal reagere inden for den tidsramme for at sikre, at du ikke mister mere end ti minutters data.
Failover metoder omfatter:
- DNS services – en DNS-tjeneste ruter trafik fra en hard .are løsning til en off-site datacenter. Dette er nyttigt til gendannelse på tværs af datacentre, hvis et helt datacenter går ned., Denne proces har imidlertid en række potentielle ulemper, herunder TTL-relaterede forsinkelser og servicenedbrydning, hvilket kan øge datagendannelsestiden.Derudover kan routingprocessen gøre failover ujævn, da Internetudbydere muligvis fortsætter med at dirigere trafik til den forkerte server, indtil deres DNS-cache er opdateret.
- hard Hardwareareløsninger-fysiske apparater opbevares på stedet. I tilfælde af at man går ned, omdirigeres trafikken automatisk til en backup-server.Denne løsning har ingen af de latensproblemer, der er forbundet med DNS failover., Det kræver dog hosting af dit backup – sted på samme fysiske sted som din origin-server. Dette betragtes generelt som en dårlig praksis, da det udsætter backup-siteebstedet for mange af de trusler, der vil påvirke din primære serverklynge (f.eks.On-edge services-Failover administreres off-site af en tredjepart, hvor data problemfrit kan dirigeres under en forstyrrende begivenhed., On-edge failover tager det bedste ud af både DNS og Hard .arebaserede løsninger—der er ingen TTL-relaterede forsinkelser eller yderligere omkostninger forbundet med vedligeholdelse af fysiske apparater. Dette sikrer minimal tab af data, så du kan vedligeholde dine RPO mål.
se, hvordan Imperva Site Failover kan hjælpe dig med høj tilgængelighed .
opfyldelse af dine gendannelsespunktsmål mål med Imperva
Imperva tilbyder en on-edge service, der giver sikkerhed, ydeevne og tilgængelighedsforbedrende løsninger til websebsteder og webebapplikationer.,den failover-funktion, vi tilbyder, gør det muligt for vores kunder at flytte deres trafik til et backup-sted inden for få sekunder, hvad enten det er en sekundær lokal server eller et datacenter placeret på den anden side af verden. Dette sikrer fortsat funktionalitet efter en forstyrrende begivenhed, så du kan indstille og vedligeholde aggressive RPO ‘ er uden at skulle bekymre dig om TTL-relaterede forsinkelser eller vedligeholdelse af apparatet og sikkerhed.,
vores failover-service forstærkes af andre funktioner med høj tilgængelighed, herunder en global CDN-platform med høj kapacitet, omfattende pakke med DDoS-afbødningsløsninger og en belastningsbalancer med applikationslag.