
o Que é objetivo de ponto de recuperação (RPO)
o objetivo do ponto de Recuperação (RPO), descreve um período de tempo em que uma empresa de operações deve ser restaurado depois de um evento perturbador, por exemplo, um cibernético, desastre natural ou de falha de comunicações.
é uma parte importante do seu plano de recuperação de desastres, e é tipicamente emparelhado com o objetivo de tempo de recuperação (RTO)—o tempo máximo para restaurar as funções críticas após um evento disruptivo.,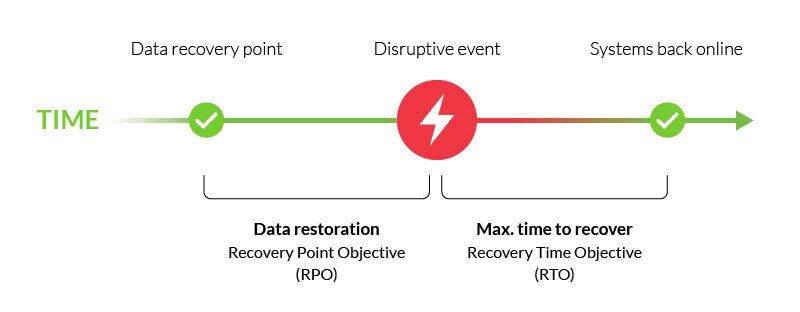
cada um dos diferentes processos da sua empresa, incluindo as redes de comunicação e a infra-estrutura, deve ter RPOs únicos, dependendo das suas funções e importância. Aqui vamos estar cobrindo como RPOs para recuperação de dados deve ser definido de acordo com suas necessidades de conformidade e metas de negócios.
definindo os seus RPOs
tipicamente, os RPOs são definidos de acordo com a frequência com que os ficheiros são actualizados. Isso garante que após uma interrupção de Serviço, suas operações restauradas contêm a versão mais atualizada de seus dados.,
por exemplo, arquivos frequentemente atualizados precisam de um curto (não mais do que alguns minutos) RPO. Isto significa que após um evento disruptivo, as operações podem ser restauradas com perda mínima de dados.os factores que podem influenciar os seus RPOs incluem:
- indústria-empresas que lidam com informações altamente dinâmicas ou sensíveis (por exemplo, registos de saúde ou transacções financeiras) actualizam os seus ficheiros com maior frequência do que as que lidam com ficheiros estáticos.armazenamento de dados – como os seus dados são armazenados (por exemplo, em aparelhos físicos, na nuvem, etc.,) pode impactar a rapidez com que pode ser recuperado após uma interrupção do serviço.considerações de Conformidade – numerosos regimes de Conformidade contêm cláusulas relativas à recuperação de catástrofes e à disponibilidade de dados. Por exemplo, a certificação SOC 2 requer um certo nível de disponibilidade de dados e integridade de processamento, o que pode afetar a quantidade aceitável de dados que podem ser perdidos após uma interrupção do serviço.
uma vez definido, os RPOs devem tornar-se as pedras angulares do seu plano de continuidade de negócio, servindo como metas para os processos que ele detalha.,
no seu plano, diferentes RPOs devem ser definidos para várias unidades de Negócio. Por exemplo, um processo de dados de missão crítica, como transações financeiras, precisa de um RPO mais curto do que Arquivos menos freqüentemente atualizados, como registros de funcionários.
A seguir estão os níveis de amostras que você pode usar ao definir os RPOs necessários para as suas unidades de Negócio:
0-1 hora
estas são operações críticas que não podem dar ao luxo de perder mais de uma hora de valor de dados., As transacções comerciais e de dados são geralmente mais elevadas em volume e mais dinâmicas, tornando a sua recreação muitas vezes impossível devido ao número de variáveis envolvidas.exemplos desta lista incluem transacções bancárias, o seu sistema CRM e registos de doentes.
1-4 horas
unidades de negócio que podem permitir a perda de dados de até quatro horas são de natureza semi-crítica. Exemplos incluem logs de chat do cliente e servidores de arquivos.
4-12 horas
unidades de Negócio abrangidas por esta categoria não podem tolerar perder mais de 12 horas de informação., Exemplos incluem dados de marketing e vendas.
13-24 horas
As unidades de negócio que compreendem esta categoria lidam com dados semi-importantes, e requerem um RPD que recua um máximo de 24 horas. Isto pode incluir os recursos humanos e departamentos de compra, que atualizam os dados menos frequentemente do que os setores de saída de uma empresa.”Failover” é o processo de troca entre seus sistemas primários e de backup durante um evento disruptivo ou um tempo de inatividade planejado do sistema (por exemplo, Manutenção de rotina).,
ao escolher uma solução de failover, é importante considerar os RPOs da sua organização para evitar perder uma quantidade inaceitável de dados ao mudar para um servidor de backup.
Por exemplo, um RPO de dez minutos significa que a sua solução de failover tem de responder dentro desse período de tempo para garantir que não perde mais de dez minutos de dados.
os métodos de Failover incluem:
- DNS services – A DNS service roads traffic from a hardware solution to an off-site data center. Isto é útil para a recuperação cross-data center, no caso de um centro de dados inteiro vai para baixo., Este processo, no entanto, tem uma série de desvantagens potenciais, incluindo atrasos relacionados com TTL e degradação do serviço, o que poderia aumentar o tempo de recuperação de dados.Além disso, o processo de roteamento pode tornar o failover desigual, como os ISPs podem continuar o tráfego de roteamento para o servidor errado até que seu cache DNS seja atualizado.soluções para Hardware-os aparelhos físicos são mantidos no local. No caso de uma pessoa cair, o tráfego é automaticamente redirecionado para um servidor de backup.Esta solução não tem nenhuma das questões de latência associadas com DNS failover., No entanto, ele requer a hospedagem de seu site de backup no mesmo local físico que o seu servidor de origem. Isto é geralmente considerado uma má prática, uma vez que expõe o site de backup para muitas das ameaças que iriam impactar o seu cluster servidor principal (por exemplo, falha da rede elétrica local ou desastres naturais).
- On-edge services-Failover is managed off-site by a third party, where data can be seemlessly routed during a disruptive event., O failover on-edge leva o melhor de soluções baseadas em DNS e hardware-não há atrasos relacionados com TTL ou custos adicionais associados com a manutenção de aparelhos físicos. Isso garante a perda mínima de dados, permitindo que você mantenha seus objetivos de RPO.
veja como a falha no Site da Imperva pode ajudá-lo com a alta disponibilidade .a Imperva oferece um serviço on-edge que fornece soluções de segurança, desempenho e disponibilidade para websites e aplicações web.,
a funcionalidade de failover que oferecemos permite que os nossos clientes movam o seu tráfego para um site de backup em segundos, seja um servidor secundário nas instalações ou um centro de dados Posicionado do outro lado do mundo. Isso garante a funcionalidade contínua após um evento disruptivo, permitindo que você defina e mantenha RPOs agressivos sem ter que se preocupar com atrasos relacionados com TTL ou manutenção do aparelho e segurança.,
nosso serviço de failover vem aumentado por outras funcionalidades de alta disponibilidade, incluindo uma plataforma global CDN de alta capacidade, um conjunto abrangente de soluções de mitigação DDoS e um balancer de carga de camada de Aplicação.